転職に向けて
これなーに
転職のタイミングで何を考えているかを書いておく。
事業会社から受託(機能)会社に行く。
考えたことや大切にしたいことなどを記載。
目次
簡単な経歴
社会人歴14年。
在籍会社数4つ。
次で5つ目。
| No | 種類 | 役割 | 在籍期間 | やったこと |
|---|---|---|---|---|
| 1 | 独立系SIer | SE | 2年 | java、C、SQL、概要設計、テスト、リリース管理 |
| 2 | 広告ビジネス(機能会社) | データサイエンス | 4.5年 | PM/PL|python、プロジェクトリード、画像解析、アクセスログ解析、外部講演、パートナー採用 |
| 3 | Deep Learning StartUP(受託・自社サービス会社) | 2年 | マネージャー | 画像解析、プロジェクトリード、グループマネージ、目標設定、評価、採用面接 |
| 4 | フリーランス | 機械学習エンジニア | 2年 | pytorch、画像解析、API開発、バッチ開発 |
| 5 | 転職サービス(事業会社) | データサイエンス | 3年 | pytorch、レコメンドアルゴリズム |
データ活用でビジネス貢献をすることをNo2以降ずっとやってきていて、
Deep Learing、画像解析・レコメンド、マネージャー、PLが強み。
データ活用は、PLからスタートしており、ゴリゴリの技術者ではなく、技術を知ってビジネス貢献するタイプ。
転職について
主にNo5の会社についての話を記述していく。
振り返ると、No5は結構多くのチャレンジがあった。
1) 初めてのレコメンドへの挑戦。
2) データ解析においてはジュニアではなく、シニアな立ち位置。
3) 初めての事業会社。
1) 初めてのレコメンドへの挑戦
個人的にはこれが大きな挑戦だと思っていた。なぜなら初めての挑戦だったから。
しかし、振り返ると1)は大したことがなかった。
画像解析でDeep Learningに慣れていて、レコメンドもDeep Learningで発展していたので、ジャンプアップできると思っていた。
実際Bertを用いたレコメンドや、RecBoleなどを用いたレコメンドを商用環境で試して、KPIを向上させることができた。
なので、1)に関してはかなり良い成果を残すことができ、個人としてもレコメンドでの成果創出や知識・スキルがついたと思う。
2)と3)が想定していない挑戦だった。
両方とも非常に重く、転職のきっかけとなっている。
2) データ解析においてはジュニアではなく、シニアな立ち位置
これは入社前に想定していなかった。1)が目に見えやすい大きな挑戦だと思っていたこともある。
具体的には、DS組織に所属していたのだが、ほぼ新卒。10人いたら7人は社会人歴3年未満のような状況だった。
また、自分以外でデータサイエンスに精通している人間もほぼいない状態だった。
こういう状況だと、詰まった時に誰かに相談ができず、Githubのissueで質問したり、コードをデバッグして理解・修正するしかなく、相談相手が欲しいと切に願う状況が続いた。
3) 初めての事業会社
No4までは、多数の会社やサービスを相手にデータサイエンスをビジネス接続していた。
例えば、様々なサービスの企画者が色んなことをやりたいと相談してくれて、それを実現するという形。
しかしNo5は、主要サービスは1つのみであり、基本的にはそのサービスをひたすらに磨いていくことが求められる。
受託会社と事業会社については、自分なりにも整理したいので少し詳細に書いてみる。
受託会社と事業会社
受託会社と事業会社でのデータサイエンスの違いみたいなものを個人的にまとめてみる。
(事業会社は1社しか経験していないため、バイアスがかなりある前提で)
| No | 項目 | 受託会社 | 事業会社 |
|---|---|---|---|
| 1 | 大切にすること | 複数のサービスへの横展開性、技術的な挑戦 | スピード、社内リソースとのシナジー |
| 2 | 世の中にサービスを出す | ハード | イージー |
| 3 | 扱えるデータや技術の種類 | 多い | 少ない |
| 4 | 好まれる動き方 | サイエンス | アナリティクス |
繰り返しになるが、主観であり、事業会社は1社しか見ていない。
また、受託的な動き方が多かったため、私自身にバイアスもある。
ここでいう事業会社は、営業部隊が多いような会社をイメージすると良いのかもしれない。
例えば、SanSanやエムスリー、Layer Xなどのような、技術に明るい人が上にいるような事業会社は
これに当てはまらないんじゃないかと勝手に思っている。
大切にすること
受託会社の戦略は、横展開にあると思う。
一つのソリューションを型化し、複数に展開していくことで売り上げを拡大していく。
サービスの提供もまさにそうで、SaaSなどにして複数社に展開していく。
そのため、受託会社は常に競合他社と比較される。
GoogleやAmazonですら、GCPとAWSの機能の違いはどうなの?とか言われる。
案件を実施する場合においても、受託会社なら直接コンペで競うことだってある。
すなわち、競合との機能的な差別化が必要となる。案件であっても、他社よりも良いコスパが大切になる。
一方で事業会社では、特定の事業の売上目標や利益目標があり、これの達成が最重要事項となる。
(もちろん、受託会社にも売上目標があるが、特定のサービスでの売上目標ではなく、様々な案件などの実施の積み上げになる。)
そしてその目標は、半年/1年/3年といったスパンで設定されており、基本的に半年間での売上目標などを立てて実施していく。
よって、スピードが非常に大切である。
また、社内のリソースの有効活用も大きなファクターである。
例えば営業の人が多ければ、営業の人たちの支援になるような取り組みはインパクトが大きい。
細かく上げるともっとあるが、大きな違いはこの辺りにあるような気がしている。
世の中にサービスを出す
これは、ほぼ間違いなく受託会社<事業会社だと思う。
事業会社は、データ活用のお膳立てができている前提で。
お膳立てとは、活用できる基盤があるという意味。
0からやりますって状況なら何故やるのかなどを頑張って伝えていく必要があり、それは非常にハードである。
すなわち、データ活用での成果創出の実績がある程度あれば、事業会社は作って世に出すことが比較的容易である。
これを作り上げられる人間は、とても貴重。
一方で受託会社の作ったものが世の中に出るには、依頼者側の都合次第だったり、期待値コントロールが重要となる。
依頼者に、「ごめんやっぱ時間取れないから無理!」って言われたら基本何もできることがなかったりする。
それでも導入してもらうことが必要なので、ここは胆力が必要だったりするが、案外「じゃあ他の案件やっておくのでまたタイミングあったらやりましょ!」って返答でも良かったりする。
何故なら、「止めるね」って言われても、やることをやっていたら受託会社にお金は入るから。
この辺りが違いかな。
しかし事業会社でイージーと言ったけど、実はハードな点もあって、
それはデータ活用に優先順位が高く位置づけられるかってポイントがある。
事業会社ではみんなで一つのサービスを磨いているので、他の人たちも色んなアイディアを持っている。
その玉石混合の中で、データ活用を何故やるのか?を説明しないといけない点は常に存在しており、ここが上の人間の力がどんなものかが大切になるポイント。
扱えるデータや技術の種類
これは受託会社>事業会社だと思う。
事業会社の扱う範囲にもよるけど。
例えば、画像データとテキストデータとアクセスログ全部使いたいってなった場合、特定の事業会社だと難しい場合がやっぱりある。
画像データはあんまり意味を持たないよねとか、アクセスログないよとか、そのデータ扱っても売上に関与できないとか。
一方、受託会社はやると決めればやれる可能性はある。(実際に、成果創出できるかどうかは話が別。)
また、新しい技術への挑戦も受託会社>事業会社だと思う。
受託会社は、大切にする観点が競合との差別化だったりするため、これは生命線と言っても過言ではない。
一方、事業会社の大切にすることは、自社サービスの売上の最大化であるため、新技術への挑戦は劣後する場合が多い。
(経営陣の大切にする観点次第)
好まれる動き方
受託会社はサイエンスで、事業会社はアナリティクスだと思う。
これは、大いにバイアスがあると思っているので、あくまで自分の振り返りの中での話。
特に、営業職が多い会社だったことが要因としてあると思う。
会社のリソースを有効活用することが、やはり会社にとってはとても大切で、
それが何を意味するのかって感じかな。
例えば営業職が多いのであれば、営業職の人を支援できると強くて、
営業職の人を支援するなら、データ活用においては解釈性が大切なので、ブラックボックスなサイエンスではなく理由がわかるアナリティクスが良いんじゃないかと感じる。
繰り返しになるけど、上の方の人間のリテラシーや戦略によるところが大きいと思う。
こんな違いを持つ、事業会社で働くという観点を、大きな挑戦であったけど見逃していたような気がしている。
なぜ転職するのか?
前置きが長くなったが、転職理由を挙げておく。
- 扱えるデータが限定的で、サイエンスとしての自分の成長を感じにくい
- 周囲のレベル感をもっと上げたい
- もっとサイエンスに理解のある会社で働きたい
アクセスログを用いたレコメンドを3年もやっていると、もっと色々なことがしたくなってきてしまった。
特に、ここまでで画像解析を用いた異常検知とかも経験していると、もっと色んなことに活用できるのになぁの思いが強くあって。
周囲のレベル感は育成でも上げられるけど、サイエンス人材がほぼ入らないので、地道すぎてキツかった。
特に上の人間のデータ活用での成功体験がアナリティクスにしかなく、サイエンスでの成果創出を見せても検討に入っていかない and ジュニアメンバーの引き上げが優先順位が高かったため、将来の期待が持てなかった。
上記二つにダイレクトで効くんだけど、やはり上の人間の過去の成功体験が鍵だと思う。
これをメインミッションにした会社だったり、色々な種類のデータや技術に触れられるところでこそ、自分はもっと活きるだろうなぁ感があったんだよね。
転職先でやりたいこと
ということで、改めて転職先でやりたいこと。
1) 周囲と協力して成果創出する 2) 多様なデータ・技術に触れる
1) 周囲と協力して成果創出する
上位陣とは、視点を大きくぶらさずに進んでいきたい。
特に、将来をどう見ているかをしっかり目線合わせをしていきたいなぁ。
人間同士なので、必ず視点はぶれるけど、そこは会話と自分のエゴの出し具合を調整して長期的に成果創出を一緒にしていきたいし、
成果創出のための武器として仕事をしていきたい。
2) 多様なデータ・技術に触れる
これは自分の転職理由として大きいため、ここはブラさないようにしたい。
幸い次の会社は、日本で最も多様なサービスを持っていて、それを扱う機会に溢れた会社だと思う。
天邪鬼なのではなく、自分の社会への提供価値を最大化するための戦略として、多様なデータ・技術に触れることをしたい。
また、当然ながら成果につながることをする。
これがないと、ただのやりたいことをやる人間になってしまう。超基本。
また、海外サービスでの売上比率も大きい会社のため、英語を頑張っていく。
アクションプラン
ここまでを踏まえて、アクションプランをざっくりと考える。
| No | 種類 | 内容 |
|---|---|---|
| 1 | インプット | 周囲がどんなサービス・どんな技術利用・どんな仕事の仕方をしているかに興味を持ち把握する。 |
| 2 | アウトプット | 何を考え、何をして、それがどういう意味を持つかを常に記述していく。 |
| 3 | 英語力 | 自分の技術視点や提供先を増やすために強化する。 |
| 4 | コミュニケーション | 短期的なタスクだけでなく、年間、中期(3年)、長期(5年10年)の話もちょいちょいしていく。 |
2,3については、もっと詳細にブレイクダウンできそうだから別記事にしようかな。
でも、こんな感じで次の職場で頑張っていきたいなぁ。
これを1年後とかに見て、振り返っていきたいね!
カルマンフィルタについて
これなーに
カルマンフィルタのメモだよ。
参考のコードを元に、細かめにメモを取っていくよ。
参考
カルマンフィルタとは
カルマンフィルタは、第1回 カルマンフィルタとは | 地層科学研究所の言葉を借りると、以下。
状態空間モデルと呼ばれる数理モデルにおいて、内部の見えない「状態」を効率的に推定するための計算手法です
観測データから内部の状態を推論し、観測できていないところを推論するようなことができるね。
これが役立つ場面は、例えば動画の物体検出。
動画の物体検出は、動画からパラパラ漫画のように画像フレームを取得して、各フレームで物体検出している。
この時、一瞬ブレてしまって画像がノイズ混じりになった結果、正しく推論できなかったフレームがあった時に、そのフレームの状態を推論して復元できる。
すなわち、物体検出の結果のスムーシングなどに使えるね。
カルマンフィルタの活用は、物体追跡(object tracking)でデファクトっぽくなっていて、以下のように組み込まれて利用されているよ。
これらは、物体検出結果とカルマンフィルタでの推論を組み合わせて同一物体かを判定することに利用していたりするよ。
コード
カルマンフィルタのコードは以下。ほぼ参考にさせてもらった記事のまま。
xとyの二次元座標上を動いていることを想定していて、0.1秒ごとに観測点のデータを得たと想定しているよ。
これをパーツごとにメモしていくよ。
# -*- coding: utf-8 -*-
import numpy as np
def kalman_filter(state, covariance, measurements, transition, external_factor, observation, noise, identity):
for n in range(len(measurements)):
# 予測(状態と共分散を更新する。)
state = transition @ state + external_factor # 行列の積として掛け算する。
covariance = transition @ covariance @ transition.T
# 計測更新
# ループの中で対象となる観測された値
measured_value = np.array([measurements[n]])
# 観測値から、予測した状態を引いて、観測の残差を計算
observe_difference = measured_value.T - observation @ state
# 観測対象の共分散を計算(抽出)
observed_error_covariance = observation @ covariance @ observation.T + noise
# カルマンゲインの計算
kalman_gain = covariance @ observation.T @ np.linalg.inv(difference_covariance)
state = state + kalman_gain @ observe_difference
covariance = (identity - kalman_gain @ observation) @ covariance
state = state.tolist()
covariance = covariance.tolist()
return state, covariance
def main():
# 1. 設定
# x, yの観測値
measurements = [[7., 15.], [8., 14.], [9., 13.], [10., 12.], [11., 11.], [12., 10.]]
# x, yの初期値
initial_xy = [6., 17.]
# 計測間隔(0.1sごとに観測している場合)
dt = 0.1
# 2. カルマンフィルタで利用する変数の設定
# x, y, x速度, y速度の初期値 (4,1)
state = np.array([[initial_xy[0]], [initial_xy[1]], [0.], [0.]]) # 初期位置と初期速度を代入した「4次元状態」
# 外部要素(4,1)
external_factor = np.array([[0.], [0.], [0.], [0.]]) # 外部要素
# 共分散行列(4, 4) 各対角要素から、x座標とy座標の分散[不確実性]は低く(=確信度が高く)、x速度とy速度の分散[不確実性]は高く(確信度が低く)している。
covariance = np.array([[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 100., 0.], [0., 0., 0., 100.]])
# 状態遷移行列(4, 4) 1行目がx座標、2行目がy座標、3行目がxの加速度、4行目がyの速度で、例えば1行目のx座標は、前のx座標の情報にdt分の速度の影響を受ける。
# 3行目はxの速度で、速度は等速と仮定しているため、前の速度と等しいようにしている。
transition = np.array([[1., 0., dt, 0.], [0., 1., 0., dt], [0., 0., 1., 0.], [0., 0., 0., 1.]])
# 観測行列(2, 4) 観測する対象を指定している意味合い。 1行目はx座標で、1, 0, 0, 0によって、x座標はx座標のみを観測対象とすることを意味する。
observation = np.array([[1., 0., 0, 0], [0., 1., 0., 0.]])
# ノイズ(2, 2)
noise = np.array([[0.1, 0], [0, 0.1]])
# 単位行列(4, 4)
identity = np.identity((len(state)))
state, covariance = kalman_filter(
state,
covariance,
measurements,
transition,
external_factor,
observation,
noise,
identity
)
print("6回の計測後の位置と速度の予測値:", state) # stateは、x座標, y座標, x速度, y速度
if __name__ == '__main__':
main()
コードメモ
1. 設定
# 1. 設定
# x, yの観測値
measurements = [[7., 15.], [8., 14.], [9., 13.], [10., 12.], [11., 11.], [12., 10.]]
# x, yの初期値
initial_xy = [6., 17.]
# 計測間隔(0.1sごとに観測している場合)
dt = 0.1
ここはシンプル。
measurementsは、観測間隔ごとの[x, y]座標を6回観測したリスト。
initial_xyは、観測開始前の[x, y]座標。
dtは、観測感覚の秒数。(動画なら1/FPSになるかな)
2. カルマンフィルタで利用する変数設定
見やすくするため、コメントを削除してます。
# 2. カルマンフィルタで利用する変数の設定
state = np.array([[initial_xy[0]], [initial_xy[1]], [0.], [0.]]) # 初期状態
external_factor = np.array([[0.], [0.], [0.], [0.]]) # 外部要素
covariance = np.array([[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 100., 0.], [0., 0., 0., 100.]]) # 共分散行列
transition = np.array([[1., 0., dt, 0.], [0., 1., 0., dt], [0., 0., 1., 0.], [0., 0., 0., 1.]]) # 状態遷移行列
observation = np.array([[1., 0., 0, 0], [0., 1., 0., 0.]]) # 観測行列
noise = np.array([[0.1, 0], [0, 0.1]]) # ノイズ
identity = np.identity((len(state))) # 単位行列
state
推論対象の状態。すなわち、x座標・y座標・x速度・y速度。
これがカルマンフィルタで推定する対象となり、stateは内部の処理で変化していく。
初期状態は、initial_xyからx座標とy座標をセットして、速度はどっちに向かっているかは不明なので0をセットしている。
external_factor
外部要素。
今回は外部要素はなしとしているが、例えば何らかの力が一定かかり続ける場合などに、それを考慮した値をセットすることになると思う。
covariance
共分散行列。対角要素以外は、x座標・y座標・x速度・y速度の共分散(関連性)で、対角要素は各分散(不確実性)を表す。
初期状態では各要素の関連性は不明なので、対角要素以外は0。
対角要素は、xとy座標は既知なので、確信度が高くて0(分散0)をセットし、x, y速度は不明なので確信度が低くて100(分散100)を置いている。
covarianceも、カルマンフィルタの処理の中で更新されていく。
transition
状態遷移行列。更新しない固定値。
各行がx座標・y座標・x速度・y速度を意味しており、例えば1行目は、x座標は(前の)x座標(1.0)とx速度(0.1)から影響を受けると定義している。
y座標も同様に(前の)y座標とy速度から影響を受け、x,y速度は、x,y速度自身からしか変化の影響を受けないように設定している。
observation
観測行列。更新しない固定値。
x座標とy座標を意味していて、x座標はx座標のみを観測対象とし、y座標はy座標のみを観測対象とすることを指定している。
noise
ノイズ行列。推定するにあたってどれくらいのブレが発生するかの度合いを示す。
identity
単位行列。共分散行列の更新時に利用する。
簡単にまとめると、
| 変数 | 変数/定数 | 次元 | 説明 |
|---|---|---|---|
| state | 変数 | (4, 1) | x座標, y座標, x速度, y速度の推定したい対象の状態の列ベクトル。 |
| external_factor | 定数 | (4, 1) | 外部からの影響の列ベクトル。今回は利用無し。 |
| covariance | 変数 | (4, 4) | x座標, y座標, x速度, y速度の共分散行列。対角要素は不確定度で、非対角要素は正なら片方が増えるともう片方も増える、負なら逆という関係。 |
| transition | 定数 | (4, 4) | 予測ステップでのみ利用。x座標, y座標, x速度, y速度がそれぞれどの要素から影響を受けるかを定義。 |
| observation | 定数 | (2, 4) | 状態の更新ステップでx座標, y座標がどの要素を観測対象にするかを定義。 |
| noise | 定数 | (2, 2) | x座標, y座標がどの程度の不確実さを持つかを定義。 |
| identity | 定数 | (4, 4) | 状態の更新ステップで共分散を更新する際に利用。 |
3. カルマンフィルタ処理
カルマンフィルタは、1)各観測点に対し、2)予測ステップと3)更新ステップを実施する。
各ステップごとに説明。
3-1: 各観測点でのループ
def kalman_filter(state, covariance, measurements, transition, external_factor, observation, noise, identity):
for n in range(len(measurements)):
measurementsに観測データ(x,y座標のリスト)が入っており、これをforループで繰り返す。
3-2: 予測ステップ
state = transition @ state + external_factor # 行列の積として掛け算する。
covariance = transition @ covariance @ transition.T
状態予測
state = transition @ state + external_factor
状態遷移行列と状態の列ベクトル(と外部要素)を用いて、次のステップの状態を予測する。
初回処理では、初期状態と定義された遷移の方法で、次の状態を予測できる。
今回の場合は、x,y座標は前回のx,y座標の値とx,yの速度で更新するが、速度は初期値で0なのでそのまま。
共分散予測
covariance = transition @ covariance @ transition.T
状態遷移行列と共分散行列を用いて、共分散を予測する。
初回処理では、仮定した共分散と定義された遷移の方法で、共分散を予測できる。(何がどうなるとどういう状態になるか?が分かるため、共分散も計算できる)
ちなみにA @ B @ A^Tの形は、BをAの空間に写像して元に戻すことをしているイメージになる。
この二つで、状態と共分散をまず予測する。
3-3. 更新ステップ
measured_value = np.array([measurements[n]])
observe_difference = measured_value.T - observation @ state
difference_covariance = observation @ covariance @ observation.T + noise
kalman_gain = covariance @ observation.T @ np.linalg.inv(difference_covariance)
state = state + kalman_gain @ observe_difference
covariance = (identity - kalman_gain @ observation) @ covariance
観測値の取得
measured_value = np.array([measurements[n]])
実際の観測されたデータを取得する。
誤差の計算
observe_difference = measured_value.T - observation @ state
実際の観測値と、予測した状態で、誤差を計算する。
observationはマスクのような役割で、観測値から内部の状態を更新する時に利用する対象(x座標とy座標)をstateから取得するために利用される。
この場合は、stateはx座標, y座標, x速度, y速度を持っているが、observationと行列積を取ることで、x座標とy座標だけが取得でき、
実際に観測したx座標とy座標から、予測したx座標とy座標を引き算して、その誤差計算ができる。
観測対象の共分散の計算
observed_error_covariance = observation @ covariance @ observation.T + noise
観測対象(x座標とy座標)の予測した共分散を取得(抽出)し、そこにノイズを加える。
抽出と表現しているのは、以下のように、共分散行列の左上のみを取得するような処理となるため。
カルマンゲインの計算
kalman_gain = covariance @ observation.T @ np.linalg.inv(observed_error_covariance)
カルマンゲインは、状態の更新時に、観測誤差や共分散をどれくらい反映させるかの重みの役割を持つ。
covariance @ observation.Tは、共分散行列の観測対象箇所を取得している。
これに、observed_error_covariance(観測対象の共分散)の逆数で行列積をとるのは、
観測対象の共分散が大きい(誤差が大きくなる)ほど予測結果への反映を小さくし、逆なら大きく反映させたいというイメージだと思う。
これにより、推定した状態と共分散を更新していく。
状態の更新
state = state + kalman_gain @ observe_difference
予測した状態(x座標とy座標)に、実際の観測値と予測値の誤差(observe_difference)にカルマンゲインとして更新すべき重みをかけて更新する。
kalman_gainが大きいと不確実性が低いので、observe_differenceを強く反映して更新する。
逆にkalman_gainが小さいと不確実性が高いので、observe_differenceを弱く反映して更新する。
共分散の更新
covariance = (identity - kalman_gain @ observation) @ covariance
予測した共分散を、どれくらいの確信度で更新するかを単位行列から引くことで確定して共分散を更新する。
covarianceは、状態の推定をするためのkalman_gainで利用される。
よって、次の処理でどれくらいのcovarianceの影響度を残すかを(identity - kalman_gain @ observation)で計算している感じだと思われる。
あんまり最後の部分自身ない・・・。。
ループ
3-3の最後で更新した状態と共分散を用いて、再度3-2: 予測ステップと3-3. 更新ステップを繰り返すことで、予測と観測からの更新で内部状態を更新していく。
これにより、未知の値がある場合にそれをそれまでの過去の観測から推論することができる。
以上で、終わり。
ちなみに、これは観測が途切れてからの次の推論だけでなく、それを重ねてさらに未来の状態も予測できる。
未来を推定するコードは以下にあります。
github.com
マハラノビス距離について
これなーに?
マハラノビス距離のメモだよ。
マハラノビス距離って?
2次元以上のベクトル空間において、ある点とある点の距離を平均や分散を考慮して計算するよ。
異常検知などで、ある点とある点の距離から異常か正常かを判断したい場合に、ユークリッド距離は一緒だけど、マハラノビス距離でみると離れていることに気づけるみたいなパターンがあるよ。
↓ こういうの。青の点1と赤の点2は、平均の黒の点からのユークリッド距離は一緒。
だけど、点の集合から考えると青は内側で、赤は外側なので赤の方が異常値だって分かるね。

xとy座標の2次元のマハラノビス距離は、以下の式。
真ん中の以下の式は分散・共分散行列の逆行列。
の場合、
になるよ。
はxの分散、
はxとyの共分散、
はyの分散。
xとyのそれぞれの分散やxとyの共分散を考慮して距離を計算するから、散り具合がわかる。
なので、ユークリッド距離が同じでも、変数の散り具合で異常判定などができるって感じね。
具体的な計算例だと、
中心座標が(4.8, 5.1)、観測座標が(6.7, 7.8)、xの分散()が2.6、yの分散(
)が2.5、xとyの共分散(
)が2.0の場合のマハラノビス距離は、
となる。
AdaptEx: a self-service contextual bandit platformを読むよ〜
これなーに
AdaptEx: a self-service contextual bandit platformのメモ。
論文:AdaptEx: a self-service contextual bandit platform
学会:Recsys(2023)
筆者:WILLIAM BLACK et al.
詳細
0. 論文概要
本論文では、Expedia Groupで広く使用されている自己サービス型の文脈バンディットプラットフォーム、AdaptExを紹介する。
AdaptExは、多腕バンディットアルゴリズムを活用して、パーソナライズした最適なユーザーエクスペリエンスを提供する。
AdaptExは、各訪問者の個別の文脈を考慮して最適な文脈を選択し、対象のインタラクションから迅速に次の一手を選択する。
従来の方法に対してコストと時間を最小限に抑えながら、ユーザーエクスペリエンスを向上させる強力なソリューションである。
本手法は、コンテンツが急速に変化する場合やコールドスタートの状況でも、迅速に最適なソリューションを提供できる。
1. 導入
Expediaでは、自身のサイト上で、B2Bネットワークと提供する建物を通じて、人々が旅行を検索し予約することを推進する企業である。
特に、アプリを用いて予約や収益を生み出している。
本アプリ上の宿泊地の情報やその選択肢の表示の最適化にて、ユーザーが予約や購入をするのをより簡単で魅力的にしている。
文脈的な多腕バンディット(MAB)は、さまざまな業界でのユーザーエクスペリエンスを最適化するための強力なツールとなっている。
ビッグデータと人工知能の進化で、企業はこれまで以上に多くの情報を手に入れることができ、各ユーザーのユニークなニーズや好みに合わせた最適な製品ソリューションに迅速に適応することがますます重要になっている。
MABの解きたい問題は、プロダクトの意思決定者がどのオプションを選択することで期待するアクション(報酬)が最大化するか?という内容である。
この報酬に対する事前分布が未知の場合、プロダクトの意思決定者は、オプションについての詳細を学ぶための欲求(探索)と、最も高い期待報酬を持つオプションを選択する欲求(利用)のバランスを取る必要がある。
文脈的なMABは、各ユーザーのユニークな文脈も考慮して異なる文脈を探索し、肯定的な結果につながる可能性が最も高い文脈を選択する。
時間の経過とともに、バンディットはすべての行動の結果から学び、報酬を最大化するための選択戦略を実施する。
AdaptExは、最適なユーザーエクスペリエンスを選択するため、設定をするだけで自動でバンディットアルゴリズムが発動し、これを実現する。
自動で実施することにより、専門的な機械学習の専門知識を必要とせず、任意の製品チームが迅速かつ簡単に文脈的なバンディットを設定およびデプロイすることが可能である。
プラットフォームの直感的なAPIは、誰もが利用可能となっている。
さらに、自己サービス型モデルにより、利用者はバンディットの設定と操作を制御することができ、特定のニーズに合わせてソリューションをカスタマイズすることができる。
従来のテスト方法は、統計的に有意な結果に達するためには各バリアントとの大量のインタラクションが必要であり、非常に時間がかかることが課題である。
一方、AdaptExは文脈的なMABを使用してユーザーの行動に適応し、はるかに大きなオプションのセットから不要な選択肢を徐々に破棄することで、検証の反復を高速化します。
AdaptExプラットフォームは、事前のモデルトレーニングを必要とせず、柔軟でスケーラブルに設計されている。
また、プラットフォームは、コンテンツの増加や、コールドスタートの状況にも対応できる。
本論文では、AdaptExによって提供されるアーキテクチャ、アルゴリズム、および使用事例を紹介し、将来についても言及する。
2. アーキテクチャ
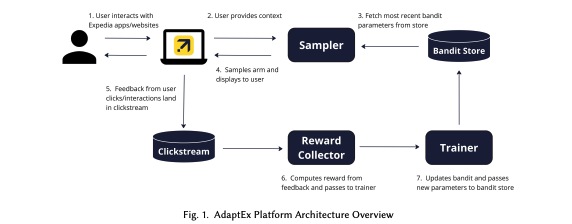
上図は、AdaptExの全体像である。
AdaptExは複数のコンポーネントから成っており、ユーザーの暗黙のフィードバックからリアルタイムで学習しながら、ユーザーに表示する最適なエクスペリエンスを適応的に選択することができる。
ユーザーがページを訪れて、例えば、休暇の目的地や旅行の日付を入力することで、明示的に機能を提供することができる。
また、デバイスタイプや時間帯などの特徴を通じて暗黙的に機能を提供することもできる。
(ユーザーのクリックやテキストの入力で提供する機能を変えることも、ユーザーの属性やアクセス時間帯などのリアルタイムな反応ではないもので提供する機能を変えることもできる。)
AdaptExプラットフォームでは、この入力などの情報をSamplerにリクエストとして渡す。
Samplerは、バンディットの推奨に従ってユーザーに「アーム」(エクスペリエンス)を返す。
このため、Samplerは定期的に最新のパラメータをBandit Storeから取得する。
Bandit Storeは、バンディットのパラメータと機能の設定を保存するMongoDBデータベースをバックエンドとするサービスである。
次に、Samplerは設定されたサンプリングアルゴリズムに従ってアームをサンプリングし、このエクスペリエンスをユーザーに提供する。
Samplerは、トラフィックに応じて水平にスケールするように設計された自動スケーリングのSpring Boot(Java製)アプリである。
これにより、リアルタイムな実験が可能となっており、季節性などのトレンドによって大きく変動する行動であっても動的に処理することができる。
さらに、Samplerにはconsistency cacheを用い、セッション全体でユーザー体験を最適化する。
ユーザーがウェブサイト上で反応をすると、その行動をKafkaを用いてクリックストリームにデータが蓄積される。
次に、Reward Collectorは、バンディットに関連するインタラクションを抽出し、Flinkを用いてユーザーごとの報酬に集約する。
ここで計算された報酬は、別のKafkaの処理を介してバッチでTrainerに渡す。
次に、Sparkを使い、Trainerが設定されたアルゴリズムに従ってバンディットのパラメータを更新する。
更新されたパラメータはBandit Storeに渡される。
これがフィードバックループの一連の流れである。
利用者は、利用したい場合はSwagger UIを使用して簡単なAPIコールをするだけでプラットフォームにアクセスでき、バンディットを適切なアーム・コンテキスト・報酬にて設定することができる。
これにより、Bandit Storeに設定が格納され、学習の準備が整ったモデルが利用可能となる。
利用者は、ユーザーコンテキスト、表示されるアーム、クリックなどの報酬イベントなど、関連するイベントのタグ付けを設定するだけで良い。
Reward Collectorがこの設定通りに動き、クリックストリームからデータを収集し、バンディットのスコアを計算することができる。
このように、利用者は新しいモデルをデプロイする必要はなく、バンディットをオフ・ザ・シェルフの方法(棚から出して速攻で使える的な意味)で利用することができ、サイトの最適化と新しい機能の展開の実験を高速に進めることができる。
3. アルゴリズム
AdaptExは、古典的な方法や文脈的な方法など、様々なバンディットアルゴリズムを採用している。
古典的な手法としては、探索(Exploration)と活用(Exploitation)のための、Epsilon Greedy (EG)法、Thompson Sampling (TS)法、指数重みアルゴリズム(Exponential Weight Algorithm)を用いている。
EG法
1 パラメータε(0から1の間の値)を設定する。(εはランダムな行動を選択する確率を表す) 2 乱数を生成し、その値がε以下であれば、全ての可能な行動からランダムに一つを選択する(探索)。 3 乱数がεより大きい場合、これまでの経験から最も報酬が高かった行動を選択する(活用)。 4 選択した行動を実行し、報酬を観測する。 5 その報酬を使用して、行動の価値の推定を更新する。 2-5のステップを繰り返す。
TS法
1 各行動に対して、その報酬の確率分布(通常はベータ分布や正規分布など)の事前分布を設定する。 2 各行動の現在の確率分布からサンプルを一つ取得する。 3 サンプルの値が最も高い行動を選択して実行する。 4 選択した行動の結果として得られる報酬を観測する。 5 その報酬を使用して、選択した行動の報酬の確率分布を更新する。 2-5のステップを繰り返す。
Exponential-weight algorithm
1 各アクションに初期の重みを割り当てる。 2 あるタイムステップで、重みに基づいてアクションを選択する。 3 選択されたアクションの結果を観測する。 4 その結果に基づいて、全てのアクションの重みを更新する。 2-4のステップを繰り返す。
これらのアルゴリズムは、フィードバックが後から得られる場合に対して、効果的である。
本プラットフォームで最も一般的に使用するアルゴリズムはTS法で、各試行の報酬分布に対する事後分布を持っており、これを用いてどのアクションをするかを決める。
そして、各タイムステップで各アームの事後分布から値をサンプリングし、最も高いサンプリング値を持つアームを選択する。
アルゴリズムがより多くのデータを得ると、事後分布の正確性が上がり、最適なアームに収束する。
補足 TSの流れ 1 サンプリング TSは、各タイムステップで各アームの事後分布から1つの値(サンプル)を取り出す。 これは、各アームが次に与える報酬の予測値を取得するためにサンプルを取得する。 2 アームの選択 取り出したサンプルの中で最も大きい値を持つアームを選択する。 これは、そのタイムステップで最も高い報酬を期待できるアームを選択する行為。 3 事後分布の更新 アルゴリズムがより多くのデータ(報酬)を観測すると、事後分布は各アームの真の報酬分布についての知識を増やしていく。 具体的には、事後分布の分散が小さくなり、ピークが真の報酬の値に近づくことを意味する。 4 最適なアームへの収束 事後分布がより集中的になるにつれて、アルゴリズムは最も報酬が高いアーム、つまり最適なアームに収束する。 すなわち、アルゴリズムが繰り返しの試行を重ねることで、最も良いアームを確実に選択する能力が向上することを意味する。
AdaptExは、contextual variableに基づいて期待報酬を推定するため、linear contextual bandit algorithmも使用している。
モデルの更新では、Bayesian Logistic Regression (BLR)とRecursive Least Squares (RLS)を利用する。
BLR
1 事前分布の設定: ロジスティック回帰のパラメータに対して事前分布(通常は正規分布など)を設定する。 2 尤度の計算: 与えられたデータと現在のパラメータの値に基づいて尤度を計算する。 3 事後分布の更新: 事前分布と尤度を組み合わせて、パラメータの事後分布を計算する。 4 サンプリング: 事後分布からパラメータのサンプルを取得する。サンプリングには、MCMCなどが使われる。 5 予測: サンプリングされたパラメータを使用して、新しいデータを予測する。
RLS
1 初期化: パラメータの初期値と共分散行列の初期値を設定する。 2 データの更新: 新しいデータポイントが得られるたびに、モデルのパラメータを更新する。 3 パラメータの更新: 最小二乗法で、現在のパラメータと新しいデータを基に次のパラメータを計算する。
BLRは、バイナリ報酬(クリック or notなどの2値)の場合によく使用され、文脈と選択されたアームを考慮して正の報酬を受け取る確率を推定するため、ベイジアン推論を使用してロジスティック回帰モデルを更新する。
RLSは、連続的な報酬(100点満点で何点をつけるか?など)の場合に、文脈と選択されたアクションを考慮して期待報酬を推定するためのオンライン線形回帰モデルを使用する。
TSとEGに加えて、Inverse Gap Weighting (IGW)も用いている。
これは、期待報酬の間のギャップに比例してアームを選択する。
Inverse Gap Weighting
1 ギャップの特定: 欠損値やギャップが存在する位置を特定する。 2 重みの計算: ギャップの前後のデータポイントまでの距離に基づいて、それぞれのデータポイントに重みを計算する。 ギャップが大きい場合、近くのデータポイントには大きな重みが、遠くのデータポイントには小さな重みをつけるようにする。 3 補間: 計算された重みを使用して、欠損値やギャップを埋めるための値を推定する。 重み付きの平均などを用いる。
ランク付け(ratingや比較して順位をつけるようなタスク)には、Cascading Banditsを使用する。
これは、ユーザーに表示するアイテムのシーケンスを選択するためにTSを使用し、各アイテムは、表示された前のアイテムを考慮してクリックされる確率に基づいて選択する方法である。
Cascading Bandits
1 表示順序: システムは複数のアイテムを順序付けてユーザーに表示する。 2 ユーザーのインタラクション: ユーザーは上から順にアイテムを評価し、興味を持った最初のアイテムに反応(クリックなど)する。それ以降のアイテムは無視されると仮定する。 3 報酬: クリックまたは選択されたアイテムのみが報酬を得る。それ以前のアイテムは報酬がなく、それ以降のアイテムは評価されないため報酬の情報がないとして扱う。
TSとCascading Bandits
1 アイテムの選択: TSを使用して、最初のアイテムを選択する。これは、そのアイテムがクリックされる確率が最も高いと予測されるものを選択することになる。 2 続くアイテムの選択: 一度アイテムが選択されると、次に表示するアイテムは、前に表示されたアイテムを考慮して選択する。 具体的には、前のアイテムが表示された後に次のアイテムがクリックされる確率に基づいて選択されることになる。 3 シーケンスの形成: ユーザーに表示するアイテム数分、これを繰り返す。 ユーザーが上から順にアイテムを評価し、興味を持った最初のアイテムをクリックするという仮定に基づき、 各アイテムは、前に表示されたアイテムに基づいて選択され、そのアイテムがクリックされる確率を最大化するように順序付けするようなイメージ。
複数の目的がある場合、その複数の目的を達成するための行動を選択する必要がある。
この場合は、Generalized Gini Index Aggrigation Functionを利用し、各目的の報酬を数値化する(スカラー化する)ことで、パレートフロント上の最適解を発見するようなアプローチをする。
パレートフロント
複数の目的関数がある場合に、その複数の目的関数の最大点を発見するアプローチ。
また、実運用時の低レイテンシ要件に対応するため、これらの実行を軽量化する必要がある。
これに対しAdaptExでは、レイテンシが発生しやすいアプリケーションのすべてのアームサンプリングリクエストの最良のアーム決定プロセスにGreedy Searchを組み込んでいる。
すべてのアームオプションを網羅的に反復する代わりに貪慾法を用いることで、リクエスト速度を短くし、良好な品質の近似ソリューションを発見する。
Greedy Searh
貪欲法。最適化問題や探索問題を解くための考え方。 「後先のことを考えず、その場その場での選択を繰り返していく」という考え方に基づき、次の行動を決める。
4. 利用例
AdaptExは、任意のプロダクトチームがMulti Arm Banditを簡単に設定できる。
チームは、仮説に最も適しているアームと文脈的特徴の設定を選択することができ、また、顧客のエンゲージメント、ロイヤルティ、予約(アクション)を含むさまざまなビジネス指標と整合するように報酬を設定することができる。
バンディットによって決定する学習とテストの流れは以下の通り。
まず、バンディットは学習フェーズとして、異なる経験を探索し、受け取ったユーザーフィードバックから学習する。
次に、学習フェーズは、バンディットによって決定された最良のバリアント(「アーム」)を固定することで停止する。
バンディットは探索を停止し、学習した結果の活用に移る。
この固定されたバンディットは、選択されたビジネス指標に対して変更が統計的に有意であることを確認するため、A/Bテストで比較していく。
この柔軟性と既存の実験方法との互換性は、Expedia Groupの複数のブランドやビジネス機能における様々な事例を生んでいる。
非文脈的テストの一例として、ウェブサイトモジュールの最適化がある。
例えば、10個以下の候補のコンテンツがある場合における、最適な選択などである。
このような場合、通常は複数のA/Bテストを実施して10個の中から最適なものを発見することになるが、本プラットフォームを使うと、1週間程度で最も良いコンテンツを見つけることができ通常の1/10くらいの期間でこれを実現する。
また、ページ上に表示するための複数のモジュールコンポーネントがあり、その組み合わせの最適化をしたい場合にも利用でき、コンテンツ・デザイン・配置をユーザーに合わせて〜100の異なる組み合わせを設定することもできる。
バンディットは、旅行のタイプや販売地点などの特徴で分類される1000以上の顧客セグメントに対して、パーソナライズされた選択も可能である。
このようなテストと最適化をしたければ、利用量(取得できるデータの数)で上下はあるが、大体2〜4週間で実現できる。
伝統的なA/Bテストでは、4週間でこれを実現することは不可能である。
さらに、AdaptExはもっと複雑なテストも実現して、最適解を発見することができた。
例えば、Hotels.comの各宿泊ページのサムネイル画像の最適化や、ページ上の数十のアイテムやモジュールのランク付けを100万を超える組み合わせの最適化の例がある。
Hotels.comの記事
最後に、AdaptExはコールドスタートの問題を克服することにも使える。
例えば、履歴データが利用できないような新しい顧客に対する最適なレコメンド戦略を決定することや、顧客の行動に関するデータがない新しいアイテムの最適な配置を見つけることができる。
文脈固有のレコメンドと、新しいアイテムの最適なプロダクト配置にAdaptExを活用することで、リアルタイムで学習するを支援することができる。
AdaptExはリリースしてから、非常に良い結果を残し続けている。
プラットフォームの成功は、MABアルゴリズムが明らかに劣っているオプションを迅速に破棄することで、大量のアームの選択を迅速にテストする能力が鍵である。
プラットフォームの高度にカスタマイズ可能なセルフサービス形式は、さまざまなビジネスニーズを持つ幅広いチームが、より迅速なパーソナライズされた機能のテストと開発を利用することを可能にした。
5. 今後の取り組み
以下の観点でAdaptEXを改良する予定である。
非線形アプローチ
時間的な制約から、線形モデルを用いたアプローチでこれまで成功を収めているが、線形モデルでは表現力が限定的であり、より複雑な報酬に対応するには不十分な可能性がある。
さらなるパーソナライゼーションを実現するため、ニューラルネットワークのような非線形アルゴリズムを採用することを検討している。
強化学習
すべてのユーザーのインタラクションが単一のステップに限定されるわけではない。
「ホームページにアクセスしてから予約するまで」は、複数のステップから為るのが一般的である。
しかし、Multi Arm Banditはデフォルトでは、この複数ステップの関連性を考慮したモデル化するようにはまだ設計されていない。
よって、連続的な意思決定支援の方法として、強化学習を活用することを検討している。
以上!
なんか分かったようなわからんような。
スモールに試してみたいんだけど、できるかな・・・???
Reciprocal Sequential Recommendationを読むよ
これなーに
Reciprocal Sequential Recommendationのメモ。
論文:Reciprocal Sequential Recommendation
学会:Recsys(2023)
筆者:Bowen Zheng et al.
詳細
0. 論文概要
Reciprocal Recommender System(RRS)は、オンラインデートや採用などのオンラインプラットフォームで広く使用されている。
既存のRRSモデルは主に静的なユーザーの好みを捉えているが、ユーザーの好みが変化することや、二つの当事者間の動的なマッチング関係を考慮していない。
動的なユーザーの好みを用いたモデリングでは、順次的な推薦システムでよく研究されていますが、ユーザーからの1方向の興味に焦点が当たっている。
そのため、これを双方向マッチングのための推薦アルゴリズムに適応させることは容易ではない。
本論文では、RRSを独自の時系列双方向マッチングタスクとして定式化し、新しいアプローチ「ReSeq」(Reciprocal Sequential recommendation)を提案する。
双方向のマッチングを実現するため、異なる時間での双方向でのattentionから得られる、きめ細かい時系列データからの類似性を学習することを提案する。
さらに、推論効率を向上させるため、きめ細かいマッチングモジュールから小規模なstudentモジュールに知識を蒸留する自己蒸留技術を導入する。
実運用時はstudentモデルを用いることで、推論時間が大幅に高速化されます。
実際のデータセットからでの実験により、提案された方法の有効性と効率性が示された。
1. 導入
相互推薦システム(RRS)は、オンラインデートや採用などのオンラインプラットフォームで広く展開されている。
これは、従来の推薦アルゴリズムとは異なり、双方向の興味を把握した上で実施することが特徴的である。
一般的に、既存のRRSの研究は大まかに、コンテンツベースの方法と協調フィルタリングベースの方法に分けられる。
コンテンツベースは主に、ユーザーの属性からユーザーの興味をモデル化します。
強調フィルタリングベースは、協調フィルタリングに基づいて長期的なユーザー間の好みを捉えた推薦をする。
しかし、ユーザーの興味は、時間とともに周囲の環境が変わるにつれて動的に変化する。
上記の二つのアプローチは、この時間の経過による変化の影響を無視している。
例えば、採用でのマッチングにおいては、個々がより多くの職業経験と資格を得るにつれて、求人探しの基準を高める傾向がある。
よって、採用のような双方向マッチングでは、動的な好みの変化を効果的にモデル化することは、正確な推薦を行うために重要である。
Sequential Recommendationは、ユーザーの動的な興味をモデル化するために、ユーザーの興味の時系列性を用いてモデリングすることでユーザーの好みを捉える。
典型的な方法として、過去の興味を元に、次に興味を持つであろうアイテムを予測する。
本論文の主張は、従来のSequential Recommendationのアルゴリズムとは異なり、ユーザーは相互推薦において二重の役割を果たし、active側だけでなく、passive側としても機能させる必要があるということだ。
よって、両当事者の動的なモデリングが必要であり、特に双方向のマッチングの文脈では難易度が高い。
技術的なアプローチとして、我々は相互推薦を独自のsequence matchingタスクとして定式化し、関与する二つの当事者の行動シーケンス間のマッチングに基づいて推薦予測を行う。
具体的には、双方向の視点で行動の時系列性を定義し、時系列での相互作用をモデリングすることで、双方向マッチングを実現する。
しかし、これを実現するためには、大きな計算コストが必要であるため、モデルの推論効率を向上させるためにself-distilationを検討する。
これらを踏まえ、本論文ではReSeqを提案する。
ReSeqは3つの特徴を持つ。
1つ目は、ユーザーの双方向の埋め込み(activeとpassive)に基づいたtransfomerネットワークを用いて双方向マッチングのための時系列データを扱う。
2つ目は、マクロとマイクロの両方で時系列の相互作用をとらえるため、複数のslaleでのマッチング予測を実施する。
3つ目は、self-distilationを推論用に実施することで、軽量な予測を実現する。
知る限り、過去にこのアプローチでの研究は存在しない。
2つの相互推薦のシナリオから、五つのデータセットで実験をし、その有用性を確認した。
2. 関連研究
双方向マッチング、Sequential Recommendation、self-distilationの3つの観点で関連研究を紹介する。
2-1. 双方向マッチング
RSS(双方向推薦システム)は、従来のユーザー/アイテムの推薦システムとは大きく異なるユーザー間のマッチングシステムである。
ユーザー間の相互的なマッチング関係を扱うため、RRSは推薦において両当事者の興味をモデリングする必要があり、これは難易度が高い。
既存のRRSは大まかにコンテンツベースの方法と協調フィルタリングベースに分類できる。
コンテンツベースの方法はユーザーの属性に焦点を当て、協調フィルタリングベースの方法は過去のユーザー同士の相互作用をモデリングする。
また、これを統合するハイブリッドモデルも存在する。
近年では、Deep Learningの利用が盛んになっている。
Matrix Factorization、Latent Factor Models、Factorization Machine、GNNsなどがある。
さらに、RRSのシナリオでより良い双方向のユーザーの好みを学習するために、複数のタイプのユーザー行動を利用するものも存在する。
これらの手法は、主に静的なユーザーの行動と属性を扱うため、時間の経過に伴う動的な変化を無視している。
本論文では、相互推薦を独自のシーケンスマッチングタスクとして定式化し、両側での動的な興味のモデリングのために双方向の行動シーケンスを活用することを提案する。
2-2. Sequential Recommendation
従来のcollaborative Filteringがユーザーとアイテムの関係に焦点を当てるのに対し、sequential Recommendationはユーザーの時系列の連続性に焦点を当てる。
最初は、マルコフ連鎖に基づく方法をとっていた。
Deep Learningの急速な発展に伴い、RNNのような多くの深層モデル利用されている。
さらに最近では、GNNベースやtransformerベースの手法も推薦タスクにおいて素晴らしい効果を示している。
これに加えて、最近の研究では、pre-training、data augmentation、regularized trainingなどの学習時のテクニックの研究も進んでいる。
上記の順次的推薦方法は、従来のユーザー-アイテム推薦において驚くべき性能を達成している。
しかし、これらは単方向なマッチングであり、双方向マッチングへのアプローチではない。
さらに、従来のSequential Recommendationで双方マッチングにアプローチする難しさは、相互推薦における両ユーザーの動的な特性の理解が必要である点である。
これらとは異なり、私たちのアプローチは、activeとpassiveの両方からユーザー行動の時系列性をモデル化し、双方向マッチングのための手法を提案する。
2-3. Self-Distillation
Knowledge Distillationは、複雑な教師ネットワークからよりシンプルな学生ネットワークへ効果的に知識を転送することができる手法である。
推薦システムの領域では、ドメイン知識の転送やモデルの圧縮[によく利用される。
ただし、最新の注意を払わないと、追加の設計と実験コストがかかってしまう。
近年では、自分自身から知識を蒸留する、self-Distilationが提案されており、主に以下の三つの一般的な自己蒸留方法が存在する。
(a) 同じネットワークの深い層から浅い層への蒸留。
(b) self-ensembleとして最新のステップのモデルを使用する蒸留。
(c) Data Augmentationに基づく蒸留。
従来の知識蒸留と比較して、自己蒸留は推薦システムの領域でさらに探究する価値がある。
双方向マッチングを時間をかけずに推論するため、本論文ではシンプルな自己蒸留フレームワークを用いる。
私たちのアプローチは、(a)の使い方に近く、より深いネットワークの出力を知識として使用する代わりに、教師モデルをマクロレベルのマッチングとして、マイクロレベルのstudentモデルに蒸留するように使用する。
3. 方法
まず、双方向マッチングの定式化を行い、次にReseqの全体を説明する。
全体像は以下。
 .
.
3-1. 問題の定式化
従来の推薦システムは、ユーザーからの単方向の興味を把握すれば良い。
これに対し、双方向推薦システムはユーザーからの興味と、アイテムからの興味(男女のデートアプリや転職サービス)が重要となる。
![]() を一つ目のユーザー、
を一つ目のユーザー、![]() をもう片方のユーザー(やアイテム)とする。
をもう片方のユーザー(やアイテム)とする。
この設定では、各側がユーザー(active)とアイテム(passive)の役割を果たすことができるため、アイテムという用語を明示的には使用しない。
代わりに、両側をユーザーと呼び、二つの側を区別するために異なる表記を使用する。
RRSにおいて好ましい推薦とは、
(a) ユーザー![]() がユーザー
がユーザー![]() に興味を示す。
に興味を示す。
(b) ユーザー![]() の特徴がユーザー
の特徴がユーザー![]() の好みと要件と一致する。
の好みと要件と一致する。
ということを指す。
これは、双方向のactiveな選択プロセスとして考えることができる。(双方が興味を持っている状態。)
RRSは、この双方向の好みをモデル化できる共同関数を学習することが目的となる。
![]()
uとvを用いて、両方の興味を計算し、これを最大化する組み合わせを探す。
本論文では、上述の設定で成り立つ。
この定式化は、RRSに対する双方向の時系列マッチングタスクであり、これまでのアプローチとは異なる。
具体的には、各時間ステップで、各ユーザーは現在の時間𝑇までの時系列な行動シーケンスを持つ。
これは以下で表現できる。
![]() ※ある時点Tまでにおいて、左側のユーザー
※ある時点Tまでにおいて、左側のユーザー![]() が右側のユーザーvへのアクションと、その逆の状態をさす。
が右側のユーザーvへのアクションと、その逆の状態をさす。
目標は、両ユーザーの歴史的な行動シーケンスの双方向のモデリングによって、両ユーザー間のマッチング度またはスコア![]() を予測する以下を作ること。
を予測する以下を作ること。
![]()
![]()
3-2. 双方向マッチングの動的な時系列行動モデリング
既存のRRSの方法は、主にユーザー属性を用いてマッチングの予測を行うか、ある時点におけるユーザーの相互作用に基づいてユーザーの静的な表現を学習する。
しかし、そのような方法は主に長期的なユーザーの興味を捉えることに焦点を当てており、時間とともに変化するユーザーの好みを無視することになる。
私たちのアプローチでは、相互推薦を独自の時系列マッチングタスクとしてモデル化し、双方のマッチングはそれぞれの動的な時系列のデータに基づいて実施する。
このセクションでは、双方向の視点の下でユーザー行動の時系列データをモデリングするための方法を紹介する。
具体的には、まず双方向マッチングにおけるユーザーの双方向表現を説明し、次にユーザーの時系列データにおけるactiveな側面とpassiveな側面の両方をエンコードするプロセスを説明する。
3.2.1 双方向ユーザーの表現学習
前述のセクションで述べたように、相互推薦における両側のユーザーのマッチングは双方向のプロセスである。
この現象は、ユーザーが相互推薦において二重の役割を果たす結果となる。
すなわち、activeに選択する側としてだけでなく、passiveに受け入れる側としても機能することになる。
したがって、双方向マッチングでは、双方向のユーザー表現を使用することになる。
双方向の視点の下でのユーザー表現学習
相互推薦のシナリオにおける両方のユーザーには、二つの異なる表現が存在する。
一つは、好みを選ぶためのactiveな選択者としての表現。
もう一つは、選ばれるために自分自身の特徴を提示することでのpassiveな候補者としての表現。
簡易的に、activeな場合を「p」、passiveな場合を「f」として表現する。
特に、一方の側のユーザーUに対しては、activeな埋め込みとpassiveな埋め込みをそれぞれ以下とする。
![]()
他方のユーザーVに対しても、以下のactiveな埋め込みとpassiveな埋め込みとする。
![]()
分解され共有する双方向のユーザー埋め込み
これまで述べてきた通り、双方向レコメンドはactiveとpassiveの両面でユーザーを扱う。
これは、双方向のユーザーの表現空間を適切に扱うべきであることを意味します。
形式的には、上記の埋め込み行列は、片方がactiveなアクションを起こした場合![]() 、もう片方はpassiveなアクション
、もう片方はpassiveなアクション![]() が起きる。
が起きる。
逆も同じく。
この双方向の関係を反映するために、ユーザーの埋め込み行列の分解を行い、分解された行列の一部を双方向の視点間で共有する。
例としては、以下のように
![]()
![]()
一方の側のユーザーのactiveな表現と、他方の側のユーザーのpassiveな表現との間で共有する。
3-2-2 双方向レコメンドの時系列行動エンべディング
分解し、共有する埋め込み表現を得たら、次にユーザーの時系列な行動をエンコードするための二つの異なる方法を提案する。
目的は、ユーザーの二つの役割の異なる動的特性に応じて、時系列データをactiveとpassiveにモデル化する。
activeな単方向の動的エンコーディング
あるユーザーがactiveな場合、行動シーケンス内の過去のマッチングユーザーはpassiveなデータとして扱う。
直感的には、推薦におけるpassiveな候補者の特徴は、ユーザーの興味と好みを示している。
よって、行動シーケンス内の過去のマッチングユーザーのpassiveな表現に基づいて、ユーザーのactiveな動的表現をエンコードする。
行動の時系列データ![]() を受け取り、まずは固定長のNになるまでパディングする。
を受け取り、まずは固定長のNになるまでパディングする。
次に、先頭に[CLS]というトークンを付与する。
さらに、学習可能な位置の埋め込み![]() と
と![]() からルックアップ操作を用いて、入力シーケンスのpassiveな埋め込み
からルックアップ操作を用いて、入力シーケンスのpassiveな埋め込み![]() を作成する。
を作成する。
その後、一般的なAttentionネットワークをシーケンスモデリングに利用する。
具体的には、典型的なトランスフォーマーのアーキテクチャは、Multi-Head Attentionの複数の層で構成されており、各自己注意の層の後にはpoint wise feed-forwardネットワーク(FFN(·)と表記)に処理が移る。
上記のシーケンス埋め込み![]() と位置エンコーディングを結合し、入力とする。
と位置エンコーディングを結合し、入力とする。
その後、計算は以下のようになる。
![]()
Hlは、lバージョン の隠れ層の出力状態で、H_0は![]() となる。
となる。
![]() は、アテンションマスクのweightで、各層で利用する。
は、アテンションマスクのweightで、各層で利用する。
我々は、activeな行動をエンコードするため、モデルが最近のユーザー行動により集中できるよう一方向の注意マスクの重み行列を使用する。
図1に示すように、対角行列の一方向のマスクと比較して、私たちのマスク行列は、情報伝達の順序と[CLS]表現のグローバルな集約を確保するために、[CLS]トークンの対応する行と列を個別に処理する。
私たちのアプローチで使用されるマスク行列は、シーケンスの最後に[CLS]トークンを追加するのと同等です。
ただし、異なる長さの行動シーケンスに個々に[CLS]トークンを挿入するよりも、私たちのアプローチは入力構築とモデル実装にとってより簡易的である。
つまり・・・
図1の左上のActive Dynamic Encodingの以下のMaskは、上から、[CLS], t1, t2, t3を示しており、水色が利用、白がmaskを指しており、t3(最新のデータ)を多くマスクせずに使うことで、最新の情報をより多く利用することで、最新の興味を強く反映することをしているらしい。(めっちゃ分かりづらいけど、多分こういうこと。。)

最後に、最終層からの出力を、ユーザーのactiveな表現として用いる。
さらに、これを二つのスケールに分割する。
![]()
![]() は、[CLS]トークンのアウトプットで、
は、[CLS]トークンのアウトプットで、![]() はユーザーのマクロ(global active dynamic)表現を指し示す。
はユーザーのマクロ(global active dynamic)表現を指し示す。
![]() は、他の出力で、
は、他の出力で、![]() はユーザーのマイクロ(fine=grained active dynamic)表現を指し示す。
はユーザーのマイクロ(fine=grained active dynamic)表現を指し示す。
passiveな双方向の動的エンコーディング
単方向のアプローチと似て、passiveな情報にもTransformerを用いる。
この文脈での違いは、行動の時系列データがactiveな役割を果たす点である。
成功しやすいpassiveとは、activeしたユーザーの好みにpassive側が近いことである。(passiveされるのは似たユーザーの場合)
入力シーケンスのアクティブな埋め込み ![]() を作成するため
を作成するため![]() の代わりに
の代わりに![]() を用いてルックアップ操作を行う。
を用いてルックアップ操作を行う。
さらに、activeな情報を扱う場合とは対照的に、ユーザーがpassiveを受けることを考えると、passiveを受ける側の特性は時間とともに大きく変わることはない。
(activeに良い人を探す場合は、その好みが時間経過で変わっていくが、探される側は時間経過では大きく考えが変わらない。)
よって、図1の右側に示されているように、マスクを時間経過の最新を重要視するようには作らず、passiveな動的エンコードを実施する。
これにより、モデルはグローバルなシーケンス表現全体でのユーザーの本質的な特性を捉える。
activeと同様に、最後の層の出力も2つのスケールに分割する。
![]()
![]() はユーザーのマクロ表現で、
はユーザーのマクロ表現で、![]() はマイクロ表現を指し示す。
はマイクロ表現を指し示す。
これを他方のユーザーでも実施することで、active側とpassive側の分散表現として扱う。
3.3 多段ステージでの時系列マッチング
ここまでで、activeとpassiveの動的表現を彼らの行動からマクロとマイクロの多段スケールとして作成することができる。
以降で、マルチスケールマッチングについて述べる。
3.3.1 マクロレベルのマッチング
前のセクションで述べたように、相互推薦における両方の当事者のマッチングは、二重視点の積極的な選択プロセスである。
よって、この二重視点の傾向をモデル化するため、active-passiveなマッチングのための2つのスコアを活用する。
図1では、一方の視点のマッチングプロセスのみが示しており、もう一方の処理が対になって存在している。
マクロレベルでのマッチング予測方法は以下の通り。

・は内積。
左辺は、u_iがv_jを好むスコア、右辺はv_jがu_iを好むスコアを指している。
3.3.2 マイクロレベルのマッチング
従来の推薦システムが固定長の静的なアイテムをマッチングターゲットとしているのに対し、私たちは、動的なユーザー行動をマッチングターゲットとして使用する。
これにより、より広くて分散した候補マッチングが生じる。
その結果、候補マッチングスペースの希薄さを軽減するために、両側のユーザー間のより詳細で微細なマイクロレベルの相互作用を取り入れて、より識別可能で正確なマッチング予測を試みる。
全体のマイクロレベルのマッチング方法は次のとおり
![]()
Time-Sensitive Micro-Level Matchingの図は以下。

activeな(時系列で最新のものが重要視される)データ![]() と、passiveな個々のデータ
と、passiveな個々のデータ![]() の間のマッチング行列を計算する。
の間のマッチング行列を計算する。
まず、![]() と
と![]() の間の関係性を計算する。
の間の関係性を計算する。
![]()
この時、Gは異なる時間ステップでのactiveとpassiveの表現間のマッチング度を示すことになる。
次に、2つの次元のattentionを通じて行列Gを集約する。
パッシブ側は、softmaxを用いてattentionの重みを計算する。
![]()
![]() は、u_iのオリジナルのactiveなエンべディングで、
は、u_iのオリジナルのactiveなエンべディングで、![]() から取得する。
から取得する。
アクティブ側は、ユーザーのactiveな動的な行動の時間感応性をモデル化するため、相対的な時間依存のAttentionの重みを計算する。
![]()
![]() は、v_jのオリジナルのpassiveなエンべディングで、
は、v_jのオリジナルのpassiveなエンべディングで、![]() から取得する。
から取得する。
αはシーケンスの終わりから減衰する学習可能な相対的な重みである。
最後に、この二つをGと集約させる。

加えて、v_jからu_iについても同様に計算し、これを合算したものが最終的なマイクロスコアとなる。
3.4 self-distilationを通じたマッチング効率の向上
インターネットの急速な発展により、オンラインプラットフォーム上のユーザー数が増加している。
しかし、同時にサービス効率の課題も浮上している。
私たちが提案したマルチスケールシーケンスマッチング方法でも、マクロレベルのマッチングは2つのシンプルな処理だが、マイクロレベルのマッチングは複雑な双方向の相互作用のため繊細な処理となっている。
しかし、マイクロレベルの処理も効率の問題を含んでいる。
distilation-technicに触発され、さまざまな分野の研究で処理効率を上げることが報告されており、私たちも実用性を考えてマイクロレベルのマッチングからマクロレベルのマッチングへのセルフディスティレーションを目指す。
具体的には、図1の「Micro-to-Macro Self-Distillation」セクションに示すように、学習中にマイクロレベルのマッチングから効率的でシンプルなマクロレベルのマッチングへの知識を転送するためにセルフディスティレーションを使用する。

この蒸留されたマクロレベルマッチングモデルを、検証、テスト、実際のアプリケーションの予測処理で利用することで、効率的な推薦が実現できる。
マイクロからマクロへのセルフディスティレーション
双方向マッチングのランキングタスクでは、一般的な分類問題とは異なり、カテゴリの分布よりもポジティブとネガティブの相対的なスコアギャップに注目する。
そこで、Margin-MSEをディスティレーションロスとして採用することで、マイクロレベルとマクロレベルのマッチング間のポジティブとネガティブのスコアマージンの最適化を目指す。
具体的には、セルフディスティレーションロスの計算式は以下。

Bはbatch_size。
+はポジティブ、-はネガティブなデータで、ポジティブとネガティブの差を最小にするようなloss設計である。
最適化の全体像
最終的なスコアは、二人のユーザーのマッチングスコアとなる。
この計算の際、activeとpassiveが二人のユーザーに存在するため、合計4つのネガティブデータが発生する。
例えば、ポジティブなセットが![]() である場合、u側のネガティブは
である場合、u側のネガティブは![]() 、v側のネガティブは
、v側のネガティブは![]() とする。
とする。
ネガティブユーザーの過去の行動シーケンスも、現在の時間𝑇から作成します。(ネガティブサンプリングは、切り取る過去時点で未来にアクションしないユーザーからサンプルする)
ネガティブインスタンスをモデルに入力すると、マクロレベルとマイクロレベルの4つのネガティブインスタンスセットを作る。
![]()
上記のネガティブインスタンスで入力に対応する要素を置き換えることで、両方のスケールで複数のネガティブインスタンススコアも計算が可能。
![]() および
および![]() を、ネガティブインスタンススコアセットとし、それぞれが4つのタイプのネガティブインスタンススコアを含む。
を、ネガティブインスタンススコアセットとし、それぞれが4つのタイプのネガティブインスタンススコアを含む。
次に、Bayesian Personalized Ranking(BPR) Lossを使用し、ポジティブインスタンスとネガティブインスタンスのランキングを最適化する。

Bはバッチサイズ。
![]() は、マクロレベルのポジティブスコア、
は、マクロレベルのポジティブスコア、![]() はネガティブスコア。
はネガティブスコア。
![]() は、マイクロレベルのポジティブスコア、
は、マイクロレベルのポジティブスコア、![]() はネガティブスコア。
はネガティブスコア。
さらに、self-distillation lossは以下のように拡張する。

上記3つのlossを結合し、最終的なloss関数の定義とする。
![]()
λとμはハイパーパラメーターで、λはマイクロとマクロの重要度の意味合いになり、μは精度と知識転送のトレードオフ具合の意味合いになる(?)。
validationとtestの時は、マクロレベルのモデルしか利用しないことで効率化を測っている。
3.5 discussion
3.5.1 時間の複雑さの分析
実サービスでの活用において、学習時に利用した様々なエンティティ自体の推論は事前に取得できます。
私たちのアプローチに関して、ユーザーの行動シーケンスのエンコーディングは、結果を事前に計算して保存しておくことができる。
よって、マッチング予測部分の複雑度について主に議論する。
マクロレベルでのマッチングは、モデルの出力次元を示す𝑑を用いて計算量はO(𝑑)となる。
これは、協調フィルタリングベースの方法やシーケンシャル推薦の方法と同じ計算量となる。
マイクロレベルでのマッチングには、まず、シーケンスの長さを示す𝑛に対して計算量はO(𝑛2𝑑)となる。
次に、2つの次元のAttentionの計算量はO(𝑛𝑑)である。
集約する操作の計算量はO(𝑛2)となる。
よって全体として、マイクロレベルの予測の計算量はO(𝑛2𝑑)となる。
オンラインプラットフォームが数万人のユーザーに対応していることを考えると、実用に耐えられないレベルである。
よって、実際のアプリケーションのモデルの効率を最適化するため、マイクロレベルからマクロレベルへのセルフディスティレーションを利用する。
3.5.2 既存の推薦方法との比較
ここでは、関連する推薦方法と簡単に比較して、私たちのアプローチの革新性と新規性を説明する。
シーケンシャル推薦方法
SASRecやBERT4Recなどの既存のシーケンシャル推薦アルゴリズムは、片方のユーザーの動的表現をエンコードするだけであり、相互推薦シナリオにおける双方向のモデリングにはなっていない。
一方、我々の提案では、ユーザーの双方向の共同モデリングを実現している。
そして、両方の推薦当事者の詳細に対して細かいマッチングを実行することで、より正確な推薦を達成する。
現在の相互推薦の研究(コンテンツベースまたは協調フィルタリング方法を問わず)では、ユーザーのモデリングは最終的に静的な表現ベクトルである。
一部の方法は、固定された属性値などに基づいてユーザーの好みをモデル化し、他の方法は、行列因子分解や潜在因子モデルを通じてユーザーの静的な暗黙の表現を学習する。
ユーザーの時系列データに基づく方法もあるが、これらはトレーニングセット内のすべてのユーザー履歴を集約するだけで、行動シーケンスの時間的な動的性を無視している。
私たちの方法は、モデルの入力を構築する際(セクション3.1)、ユーザーの行動をエンコードする際(セクション3.2)、および双方向のユーザーマッチングを予測する際(セクション3.3)に、ユーザーのアクティブおよびパッシブの視点の両方の動的性を考慮する。
4 実験
4.1 実験設定
4.1.1 データセット
2つの種類のシナリオで5つデータセットでの実験を行った。
(シナリオ 1) オンライン採用
中国の転職サイトのデータを用いて評価する。
100日以上のデータからデータセットを作成し、個人情報を弾いている。
候補者と採用担当者が面接に至ったペアをポジティブとして利用している。
(シナリオ2) Question-Answer
StackExchangeのデータを用い、質問者と回答者のマッチングとして評価する。
回答者側には、回答履歴に沿った質問を提示し、質問者側には回答できる人を紹介するような提示である。
データ準備について、まず5-coreフィルタリング(5つ以上のアクション、被アクション)を行い、データをスクリーニングした。
その後、時系列のデータを作成していった。
各アクションデータは、データのリークを排除するため、その瞬間までのデータのみを使用する。
三つの転職のデータセットにおいて、データの最後の2週間を検証とテスト用として採用し、残りのデータを学習に利用した。
また、QAのデータセットは、8:1:1の比率で時間で分割した。
データセットの概要は以下の通り。

4.1.2 ベースラインモデル
ReSeqと比較するために、以下のモデルを用いた。
BPR/LFRP/NueMF/LightGCN/SASRec/SSE-PT/BERT4REC/FMLP-Rec/PJFNN/IPJF/PJFFF/DPGNN
これらは、強調フィルタリングベース(BPR/LFRR/NeuMF/LightGCN)と、sequential recommendation(SASRec/SSR-PT/BERT4REC/FMLP-Rec)と、person-job-fitモデル(PJFNN/BPJFNN/IPJF/PJFFF/DPGNN)に分類できる。
person-job-fitについては、テキスト情報が必要となるため、転職データセットでのみ利用した。
4.1.3 評価の詳細
HIT Ratio・NDCG・MRRでTOP5を用いて評価した。
ネガティブサンプリングはそれぞれ100ずつ取得して利用している。
各データの瞬間以前のデータのみを利用し、リークを防いでいる。
全てのモデルでoptimizerにはAdamを用い、gridサーチでハイパーパラメータチューニングを実施している。
learning rateを{0.005, 0.001, 0.0005, 0.0003, 0.0001, 0.00001}の間で変化させた。
平等な評価のために、エンべディングの次元数は64に固定した。
weight decayは1e-5を利用。
10epochごとにearly stopping判定をする。
全ての実験をRecBoleで実施した。
4.2 結果

転職データセットの結果を上に示す。
person-job-fitのロジックが比較対象に含まれる。

QAデータセットの結果を上に示す。
これらの結果から、以下がわかる。
協調フィルタリングベースの[GCN/MLPなどのモデル]は、シンプルな行列因子分解の手法[BPR/LFRR]と比較して、良い精度を示している。
これは、インタラクションの粒度が増加することが、静的な表現の場合であっても、推薦の精度にプラスの影響を与えることを示している。
sequential recommendationは、協調フィルタリングベースより良いパフォーマンスを達成している。
これは、時系列なデータに基づいてユーザーの好みを動的にモデル化することが有利に働いていると考えられる。
さらに、FMLP-Recはトランスフォーマーベースのモデル(SASRec、SSE-PT、BERT4Rec)と比較して、かなり良い結果を達成している。
これは、FMLPの学習可能なフィルタリング層が、効率的にノイズを減少させる能力があり、これが効果的であることを示唆している。
転職データセットでの結果には、person-job-fitの手法の結果も含まれる。
ユーザーの履歴書と求人の説明だけに依存するモデル(PJFNNとBPJFNN)は、より高品質で大量のテキストデータを含むTechnologyの結果がDesignやSaleのデータセットと比較して良いパフォーマンスを発揮しているため、データ量に大きく依存することがわかる。
テキストとCollaborative Filteringを組み合わせたハイブリッドモデル(IPJF、PJFFF、DPGNN)の中で、DPGNNが最も優れたパフォーマンスを達成しており、これは相互推薦における双方向の選択プロセスの重要性が現れていると考えられる。
全体として、すべてのベースライン方法と比較して、提案手法のReSeqは、2つのシナリオの5つのデータセットのほぼ全てで最も良い結果を達成している。
比較した他の手法と異なり、私たちは相互推薦を独特のシーケンスマッチングタスクとして定式化し、両方の当事者の動的な行動シーケンスに基づいてマッチング予測を行う。
そして、処理高速化のため、自己蒸留技術を導入して、マイクロからマクロレベルのマッチングまでの知識を蒸留し、類似性の計算を大幅に高速化する。
その結果、ReSeqは効果的かつ効率的な相互推薦方法となっている。
4.3 アブレーションスタディ
ReSeqの主な貢献は以下4つ。
- activeとpassiveに分解された埋め込み
- 行動シーケンスのエンコーディング
- マッチング予測
- 効率の向上
これらの有効性を確認するため、DesignおよびStackOverflowのデータセットでアブレーションスタディを実施した。
具体的には、ReSeqの以下の4種類を確認した。
• ReSeq w/o DSE:埋め込み行列の分解と共有の処理を削除し、ユーザーの4つの埋め込み行列を直接学習する。
• ReSeq w/o MASK:activeとpassiveのマスクを、同じ双方向マスク行列に置き換える。
• ReSeq w/o TSA:マイクロレベルのマッチングでの時間を考慮した係数の利用を、平均集約に変更する。
• ReSeq w/o SD:自己蒸留損失を削除する。
以下に結果を示す。

この結果から、どれも削除してしまうと、パフォーマンスが低下することがわかる。
これは、ReSeqのすべてのコンポーネントが重要な役割を果たしていることを指す。
4.4 更なる考察
4.4.1 ハイパーパラメーターチューニング
このセクションでは、2つの損失関数の係数を変更した実験で、モデルのロバスト性を評価する。
以下に、2つのデータセットを用いてλとμを変化させた時の結果を示す。

各損失係数について、NDCG@5nの変化を2つ(QとAやcandidateとcompany)のそれぞれと平均で、確認した。
損失係数𝜆については、0.5と1から10の範囲で調整し、ポジティブデータがネガティブに比べて不足している場合の影響を調査する。(λが大きいほうが、ポジティブ割合が減る)
係数𝜆の増加に伴って、モデルのパフォーマンスは徐々に向上する。
値が5のとき、ReSeqは最高のパフォーマンスを達成し、𝜆のさらなる増加は大きなパフォーマンスの低下をもたらさなかった。
これはこのモデルの堅牢性を反映していると言える。
自己蒸留損失係数𝜇は、{0.0001, 0.001, 0.003, 0.005, 0.01, 0.05, 0.1}の範囲で調整した。
𝜇がそれぞれ0.005および0.01に設定されたとき、モデルは2つのデータセットで最高の結果を達成した。(Designは0.003では???)
小さすぎるμは、マイクロレベルとマクロレベルの間での知識の効果的な転送ができない。(μが大きいとdistillationを重視する。)
一方、μが大きすぎると、モデルがランキングの最適化を無視して全体の精度が下がる。

4.4.2 デプロイ効率性について
self-distillationの効果を確認するため、DesignとStackOverflowで、SASRec、ReSeq、およびReSeq w/o Self-Distillationのマッチング予測の効率を比較した。
実験は、Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz CPUと12GB NVIDIA TITAN V GPUを備えたLinuxシステムマシンで行った。
公平な比較のため、すべての方法をPyTorchフレームワークで実装し、バッチサイズなどの共通のパラメータを統一させた。
速度の比較は具体的には、テストデータとして利用したもののバッチごとの平均マッチング予測時間をカウントして比較する。
さらに、PyTorchのsynchronize関数を通じてプロセスの同期を維持して実施した。
以下に結果を示す。

ReSeqはSASRecよりもわずかに遅い。
本手法は、双方向マッチのための処理であるため、速度が遅くなってしまうのは避けられない。
しかし、自己蒸留なしの場合はSASRecの何十倍もの時間がかかっており、自己蒸留によって実用的なレベルに抑えられている。
4.4.3 テキストデータの影響
採用データセットでテキストデータを追加する実験をした。
具体的には、追加の予測レイヤーを備えた事前学習されたBERTから得る、テキストマッチングスコアを、マクロレベルのマッチング予測に組み込んで利用した。
以下に結果を示す。

結果から、シンプルなテキストデータとの組み合わせで、3つのデータセットの両方の視点で基本的に精度向上が見られる。
特に、ReSeqはTechnologyデータセットでより効果が高かった。
なぜTecjnologyが特に効果的だったかを考察すると、テキストの品質と量がデータセットごとに顕著に異なり、technologyはこれがよかったのではないかと考えている。
したがって、テキストの品質と量が他の2つのデータセットを大幅に上回るTechnologyデータセットでは、テキストの強化の効果がより顕著だったのではないかと考察している。
上記の結果は、私たちの方法が補足情報を取り入れれば更なる改善ができることを示している。
もちろん、このシンプルなテキスト強化方法にはいくつかの制限があるかもしれませんが、将来的にはテキストや他の情報を統合するためのより合理的なアプローチを考慮する予定である。
5 結論
本論文では、ReSeqという名前の相互的な順序的推薦方法を提案した。
双方のユーザーの動的な興味をモデル化するため、相互的な推薦を時系列のマッチングタスクとして定式化した。
具体的には、activeとpassiveの両方の視点からユーザーの時系列の行動を異なるモジュール設計でエンコードする。
その後、マルチスケールのシーケンスマッチングを通じて、マクロおよびマイクロの両方のレベルで包括的かつ詳細なシーケンスの相互作用の特徴を抽出する処理をする。
さらに、詳細な相互作用によって増加する推論時間を軽減するため、マイクロからマクロへの自己蒸留を介してモデルの現実での利用可能性を向上させた。
実際のデータセットでの実験では、私たちのアプローチがRRSの2つの視点で他手法を上回ることが示せた。
将来的には、テキスト情報やカテゴリなどの複数の補助的な順序的特徴を、普遍的で効果的かつ効率的な方法で私たちのフレームワークに組み込む。
さらに、事前学習、データ増強、および自己教師付き学習技術を含む、相互的な順序的モデルのトレーニング中に疎性の問題をさらに軽減したいと考えている。
以上! メーーーちゃ難しいな。でもなんか凄い勉強になった
【読書_2冊目】初めての課長の教科書
書籍情報
| 項目 | 内容 |
|---|---|
| タイトル | はじめての課長の教科書 |
| 発売年 | 2008 |
| 読んだ日 | 2023/9/6 |
| おすすめ度 | ⭐️⭐️⭐️⭐️⭐️ |
読んだ理由
経緯
- 昔のバリバリエンジニアだった同僚が現在部長になっていて、おすすめしてくれた。
- プレイヤーからマネージャーに移るので、ぴったりだと思った。
学びたいこと
- マネージャーの心得
- マネージャーの型
ざっくりと感想
課長とはなんぞやを改めて考えさせられた。
メンバーのモチベーションの向上と維持が最重要、社内政治での政敵との付き合い方、英語の勉強、読書あたりが刺さったかな〜
あとは、上司に情報をとにかく流すみたいなのは、今日からでもできるなぁと思った。
刺さった内容
1章 課長とは何か
課長とは、組織の中堅に位置し、より末端に近い組織構成員を管理する立場。グループリーダーやマネージャーとも呼ばれる。
課長とは、部下の功績や能力を評価することが正式に認められている最下位のポディション。
課長と部長の違いとは、課長にとって予算とは達成しなければならないもの、部長にとっては人を動かす政治的なツール。
部長は課長と違い「自分の専門外の知識を持った部下」を管理監督しなければならない。
現場の知識は、課長の方が遥かに多く、基本的に部長は「責任は俺が取るからあとは自由にやれ」というスタンスとなる。
課長と部長の違い

課長と経営者の違いとは、マネジメントとリーダーシップの違い。
優れたマネージャーであっても優れたリーダーであるとは限らずまた逆もしかり。
マネジャーの出発点は部下一人ひとりだ。マネジャーは部下の才能、スキル、知識、経験、目標といった要素を観察し、それをもちいて彼らがそれぞれ成功できる将来計画を立てる。マネジャーは、部下一人ひとりの成功に専念する。リーダーは違ったものの見方をする。リーダーの出発点は、自分が描く未来のイメージだ。よりよい未来こそ、リーダーが語り、考え、反芻し、計画し、練り上げるものだ。このイメージが頭のなかではっきりしたかたちをとって初めて、リーダーはまわりの人々を説得すること─私が思い描く未来で、あなたも成功できる─に関心を向ける。しかしそういった活動のすべてを通じて、リーダーが専念するのは未来である。
課長として最も大切なのは「部下のモチベーションを管理する」こと。
形式的な成果主義によって外側から圧力をかけて部下を動かそうとするのではなく、部下の内部から湧き上がるモチベーションを刺激することで、部下みじからが高い業績に向かっていくようにする。
部下のモチベーション管理にあたっては、モチベーションを高めることだけではなく、モチベーションを「維持する」という視点がとても重要になってきます。 部下を一人の人間として気にかけ、能力だけでなく、もっと人間性に興味を示してやるということが、お金よりも重要です。部下を、目標を達成するための「機能」として考えるのではなく、血の通った尊厳を持った一人の「人間」として扱うことが本質なのです。
成果主義では、メンバーを成果を出すための「機能」としてみるが、課長に必要なのはメンバーを「人間」としてみる必要があり、成果主義はここでは機能しない。
ただし、課長以上には成果主義を適応し、メンバーには成果ではなくプロセスを大切にするようなやり方が良い。
課長の大きな役割の一つに、異なる価値観を持つ世代間の「通訳」となることが挙げられる。
時に人はコミュニケーションでぶつかるが、顧客のことを大切に思う気持ちは、新旧世代のどちらでもカギとなる大切なものであり、これをキーにして新旧世代が歩み寄れるはず。
この思い出、異なる価値観を持つ世代を繋ぐのが課長。
課長には、情報が集まる。
 .
.
「役割分担が明確な企業」というのは、現場情報は経営者まではほとんど伝わらず、逆に経営情報も末端の社員に伝わることが少ない企業です。「フィルタリングによる情報量の減少が大きい組織」と理解してもいいでしょう 企業によって「風通しの良い企業」と「役割分担が明確な企業」という組織スタイルの違いはあっても、先にも課長の特徴として取り上げた(1)課長のところで経営情報と現場情報は交差し、(2)社内の情報は課長に向かって集まり、(3)課長は現場情報と経営情報をバランス良く持っている、という3つの事実だけは共通しているということは強調に値します。社内の課長が集う「課長会」が活発に行われるような「課長の元気が良い企業」こそが新時代を勝ち抜く企業に共通する特徴なのです。
この辺は、役割定義及びその染み出しの重要性であり、それをコントロールできるのが課長。という感じ。
課長は、例外を発見してそれに適切に判断を下すことができる力が求められる。
中間管理職は、ルーティン・ワークから逸脱するような例外をすばやく発見し、バランスの取れた決断を下すことが役割になります。 例外的な問題や機会の中には中間管理職として対処するには大きすぎるものも存在します。 それを判断するには、上場企業であれば「自社の株価に影響するようなレベル」、上場企業でなければ「マスコミに知られたら記事にされるようなレベル」 というのが簡単な目安になるでしょう。 基本的には、判断に少しでも迷うようなら、部長や経営陣に相談するのが良いでしょう。
中間管理職は、現場から「重要な現場情報」を引き上げ、それを「経営者が描いた大きなビジョン」をつなぐために知恵を絞る「ミドル・アップダウン」な活動をするのです。
まとめ
課長とは、部下のモチベーションの向上と維持が重要である。
課長は、「顧客第一主義」という共通の価値観を軸に世代間の価値観の通訳をする。
課長は、経営者が発信する経営情報と末端社員が持つ現場情報、2つの情報をバランスよく持つ情報伝達のキーパーソンである。
2章 課長の8つの基本スキル
スキル1 部下を守り安心させる
良い話題は、課長としての職務にはあまり意味がありません。むしろ「入金が遅れそうだ」といった「悪い情報」がどれほどすばやく部下から上がってくるかが、課長の死活問題となります。 部下も人間ですから、必ず失敗をします。しかし、課長が部下の失敗をそのまま部長や経営者に伝えてしまってはなりません。 もちろん同じ失敗を繰り返さないよう部下を指導することも大切です。 ですが、部下が失敗したことを社内で宣伝したとしても、誰もハッピーになりません。 部下が「何かあれば課長に守ってもらえる」という実感を持って、安心して業務に専念できるような環境を作ることが、最も大事。
スキル2 部下を褒め方向性を明確に伝える。
褒めるとはおだてるとは違う。褒めるとは、感謝の意を示しつつ部下の進むべき方向をはっきりと示すこと。
褒める際は、なぜ褒められたのかを正しく伝えることが重要。
まず部下の正しい行動を褒め、さらに小さいものでも部下が出した成果を、その部下の能力や実績と照らし合わせて評価する。 褒めるときは人前で褒める。 明らかなハイパフォーマーに対しては、褒め慣れているので、第三者から伝えてもらうのも手。 例えば、仲の良い顧客に根回しをして褒めてもらったりするのも効果的。
スキル3 部下を叱り変化を促す
人間は、自分から「変わる」ことにはあまり抵抗しないのですが、自らを誰かに「変えられる」ことにはとても強く抵抗する。
こっそり指摘する。失敗なしに成長はないので、これは誰にとっても必要なプロセス。
部下を叱る際は、「自分もかこにこういう失敗をした」とか「役員の〜〜もやっていた」などの言い方を入れると良い。
叱る場合のフェーズは、事実関係を確認する→問題に至った原因を究明させる→部下が気づかなければ、直接原因を伝え部下を叱る→感情のフォローアップをする になる。
スキル4 現場を観察し次を予測する
部下を監視するのではなく、注視する。
教育をしたら部下の能力を信頼し、部下の思う通りに仕事をさせるというのが現代的な管理手法。
スキル5 ストレスを適度な状態に管理する
ストレスには4つの段階があり、(超軽い、軽い、重い、超重い)、イノベーションが起きるのは重い時。基本は軽いと重いを行ったり来たりさせる。
スキル6 部下をコーチングし答えを引き出す
コーチングは、以下の目的で実施する。
潜在能力を引き出す。
思考プロセスを鍛える。
モチベーションを高める。
心構えとしては、以下。
部下の価値を認め、可能性を信じる。
秘密を固く守り、信頼関係を築く。
アドバイスや指示・提案はしない。YES/NOで答えられるような質問は避ける。「なぜ?どうして?」を聞くときは、非難の意味を込めない。
スキル7 楽しく没頭できるように仕事をアレンジする
フローと呼ばれる、没頭状態にする。
フローは、以下の条件で発動する。
やることの目的とかちが明確になっている。
活動を自分でコントロールできる。
活動の難易度がちょうど良い。
活動中に邪魔が入らない。
活動の最中、その成功と失敗が明確になる。
スキル8 オフサイト・ミーティングでチームの結束を高める
居酒屋コミュニケーションの時代は終わった。
業務の中で、居酒屋での会話のような雰囲気を作ったロングミーティングをする。
3章 課長が巻き込まれる3つの非合理なゲーム
予算管理、人事評価、社内政治。
予算管理は、全ての数値目標について説得力のあるストーリーを準備する。
人事評価は、部下のモチベーションを高めるコミュニケーションの機会。できれば全ての部下に高い評価を与える。
低い人事評価で部下を驚かすことがあってはならない。心の準備ができるように事前にサインを十分に送っておく。
低い人事評価の理由をクドクドと述べない。今後に期待していることを伝え、スキルアップの機会などを提案し部下を勇気づける。
社内政治は、悪ではなく必要なもの。ある種のツール。
社内のキーマンをしり、その権力範囲を知る。
自らがキーマンにとって有用な人材になる。キーマンにとっては、ギブ&ギブくらいの気持ちで。
具体的に実践こととして、少し仲良くなったキーマンには、とにかく情報を流す。
至る所で政敵を褒める。褒めることで敵が減るし、褒めている人を落としている人に人望は集まらない。
政敵を攻撃することは、知らず知らずのうちに、自分自身を攻撃していることになる。
4章 避けることができない9つの問題
問題1 問題社員が現れる
問題社員が現れた場合、課長としての能力を社内でアピールするチャンスでもある。
問題社員(能力が低い社員)でもできる仕事を見つけて与えてあげることが重要。こういう社員も含めて、成果を出していくという姿勢が評価につながる。
問題2 部下が「会社を辞める」と言い出す
まずは「どうして辞めたいか?」を理解する。
知らずに告げられた場合、これを把握するネットワークが作れていないことを課長は反省すべき。
問題3 心の病にかかる部下が現れる
男性よりも女性の方が、他者の異常に気付きやすいので、女性の方に最近不調そうな人いる?って聞いてみるのも手。
問題4~7はスキップ。海外の部下の話など。
問題8 昇進させる部下を選ぶ
部下を昇進させるときに決して曲げてはならないのは、イエスマンを選ぶのではなく、多少トゲがあっても必ず「本物」を昇進させるということです。 「本物」とは、個人的な利害ではなく、会社全体の利害を考えて会社を成長させることができる人物、 さらに従業員の皆をハッピーにするために、無私に優れた仕事をすることができる人物のことです。
問題9 ベテラン係長が言うことを聞かなくなる
こう言う場合は、係長と他を競わせると勝手に成果を出していってくれてうまくいく。
5章 課長のキャリア戦略
リーダーシップの本質は、価値観や雇用形態を超えて、周囲の多くの人々から「この人と一緒に仕事をしたい」と思われることにある。
戦略1 自らの弱点を知る
米国海軍の飛行訓練では「大胆不敵なパイロットは長生きできない」と教えられるそうです。キャリア戦略というと前を向いて前進するイメージですが、キャリア戦略の構築は、いつもバックミラーを見ること(振り返り)から始まります。 課長ぐらいになれば、これまでにこなしてきたルーティンワークも相当な数になるはずです。 そんな経験から、自分の典型的な「負けパターン」を洗い出しておきます。 自分の弱点を根本的に克服することは困難でも、同じ失敗はテクニックで回避できるからです。
基本的な仕事のスタンスは、大手柄を立てようなどと考えず、自らの負けパターンを知り、注意深くそれを回避しつつ、極力失敗を少なくするといった形であるべきです。
一般的に見られる負けパターンの入り口としては「怒り」の感情の処理が挙げられます。 この感情のコントロールが下手だと、ビジネスにおける成功を逃すのは確実です。
もう一つの典型的な負けパターンの入り口としては「自分の理解を過大評価する」ということが挙げられます。 手柄を独り占めしようとして物事を自分だけで進めることを常に避け、問題が複雑すぎるような場合は、時間稼ぎをしてでも、その問題を解決するのに最も適切な人物を探すことを躊躇わないということです。
戦略2 英語力を身につける
あなたの「典型的な1日」を思い出してください。その「典型的な1日」の中に、英語のトレーニングの時間が入っていないとするならば、非常に危険です。
戦略3 緩い人的ネットワークを幅広く形成する
コネの8割は弱い絆である。
戦略4 部長を目指す
自分の課を成長させて部に昇格させる。
自分に関わる周囲のお同僚に対して昇進を届けるという方法が、課長が部長になる王道だと思います。
戦略5 課長止まりのキャリアを覚悟する
昇進はもういいやと決断すると、想像以上に自由な発想で仕事ができるようになり、思わぬ好成績をあげて昇進することがある。
戦略6 社内改革のリーダーになる
キャリアを考えるのであれば、仮にそれが無駄だとわかっていても、それでも自社を変える努力をし、社内で改革のリーダーになるべきです。
戦略8 ビジネス書を読んで学ぶ
先人の知恵を借りる。