これなーに
AdaptEx: a self-service contextual bandit platformのメモ。
論文:AdaptEx: a self-service contextual bandit platform
学会:Recsys(2023)
筆者:WILLIAM BLACK et al.
詳細
0. 論文概要
本論文では、Expedia Groupで広く使用されている自己サービス型の文脈バンディットプラットフォーム、AdaptExを紹介する。
AdaptExは、多腕バンディットアルゴリズムを活用して、パーソナライズした最適なユーザーエクスペリエンスを提供する。
AdaptExは、各訪問者の個別の文脈を考慮して最適な文脈を選択し、対象のインタラクションから迅速に次の一手を選択する。
従来の方法に対してコストと時間を最小限に抑えながら、ユーザーエクスペリエンスを向上させる強力なソリューションである。
本手法は、コンテンツが急速に変化する場合やコールドスタートの状況でも、迅速に最適なソリューションを提供できる。
1. 導入
Expediaでは、自身のサイト上で、B2Bネットワークと提供する建物を通じて、人々が旅行を検索し予約することを推進する企業である。
特に、アプリを用いて予約や収益を生み出している。
本アプリ上の宿泊地の情報やその選択肢の表示の最適化にて、ユーザーが予約や購入をするのをより簡単で魅力的にしている。
文脈的な多腕バンディット(MAB)は、さまざまな業界でのユーザーエクスペリエンスを最適化するための強力なツールとなっている。
ビッグデータと人工知能の進化で、企業はこれまで以上に多くの情報を手に入れることができ、各ユーザーのユニークなニーズや好みに合わせた最適な製品ソリューションに迅速に適応することがますます重要になっている。
MABの解きたい問題は、プロダクトの意思決定者がどのオプションを選択することで期待するアクション(報酬)が最大化するか?という内容である。
この報酬に対する事前分布が未知の場合、プロダクトの意思決定者は、オプションについての詳細を学ぶための欲求(探索)と、最も高い期待報酬を持つオプションを選択する欲求(利用)のバランスを取る必要がある。
文脈的なMABは、各ユーザーのユニークな文脈も考慮して異なる文脈を探索し、肯定的な結果につながる可能性が最も高い文脈を選択する。
時間の経過とともに、バンディットはすべての行動の結果から学び、報酬を最大化するための選択戦略を実施する。
AdaptExは、最適なユーザーエクスペリエンスを選択するため、設定をするだけで自動でバンディットアルゴリズムが発動し、これを実現する。
自動で実施することにより、専門的な機械学習の専門知識を必要とせず、任意の製品チームが迅速かつ簡単に文脈的なバンディットを設定およびデプロイすることが可能である。
プラットフォームの直感的なAPIは、誰もが利用可能となっている。
さらに、自己サービス型モデルにより、利用者はバンディットの設定と操作を制御することができ、特定のニーズに合わせてソリューションをカスタマイズすることができる。
従来のテスト方法は、統計的に有意な結果に達するためには各バリアントとの大量のインタラクションが必要であり、非常に時間がかかることが課題である。
一方、AdaptExは文脈的なMABを使用してユーザーの行動に適応し、はるかに大きなオプションのセットから不要な選択肢を徐々に破棄することで、検証の反復を高速化します。
AdaptExプラットフォームは、事前のモデルトレーニングを必要とせず、柔軟でスケーラブルに設計されている。
また、プラットフォームは、コンテンツの増加や、コールドスタートの状況にも対応できる。
本論文では、AdaptExによって提供されるアーキテクチャ、アルゴリズム、および使用事例を紹介し、将来についても言及する。
2. アーキテクチャ
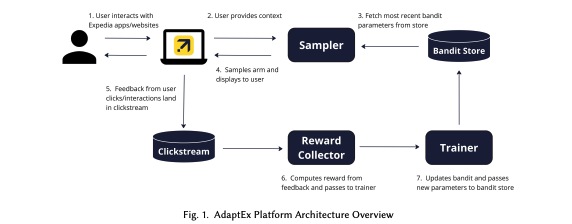
上図は、AdaptExの全体像である。
AdaptExは複数のコンポーネントから成っており、ユーザーの暗黙のフィードバックからリアルタイムで学習しながら、ユーザーに表示する最適なエクスペリエンスを適応的に選択することができる。
ユーザーがページを訪れて、例えば、休暇の目的地や旅行の日付を入力することで、明示的に機能を提供することができる。
また、デバイスタイプや時間帯などの特徴を通じて暗黙的に機能を提供することもできる。
(ユーザーのクリックやテキストの入力で提供する機能を変えることも、ユーザーの属性やアクセス時間帯などのリアルタイムな反応ではないもので提供する機能を変えることもできる。)
AdaptExプラットフォームでは、この入力などの情報をSamplerにリクエストとして渡す。
Samplerは、バンディットの推奨に従ってユーザーに「アーム」(エクスペリエンス)を返す。
このため、Samplerは定期的に最新のパラメータをBandit Storeから取得する。
Bandit Storeは、バンディットのパラメータと機能の設定を保存するMongoDBデータベースをバックエンドとするサービスである。
次に、Samplerは設定されたサンプリングアルゴリズムに従ってアームをサンプリングし、このエクスペリエンスをユーザーに提供する。
Samplerは、トラフィックに応じて水平にスケールするように設計された自動スケーリングのSpring Boot(Java製)アプリである。
これにより、リアルタイムな実験が可能となっており、季節性などのトレンドによって大きく変動する行動であっても動的に処理することができる。
さらに、Samplerにはconsistency cacheを用い、セッション全体でユーザー体験を最適化する。
ユーザーがウェブサイト上で反応をすると、その行動をKafkaを用いてクリックストリームにデータが蓄積される。
次に、Reward Collectorは、バンディットに関連するインタラクションを抽出し、Flinkを用いてユーザーごとの報酬に集約する。
ここで計算された報酬は、別のKafkaの処理を介してバッチでTrainerに渡す。
次に、Sparkを使い、Trainerが設定されたアルゴリズムに従ってバンディットのパラメータを更新する。
更新されたパラメータはBandit Storeに渡される。
これがフィードバックループの一連の流れである。
利用者は、利用したい場合はSwagger UIを使用して簡単なAPIコールをするだけでプラットフォームにアクセスでき、バンディットを適切なアーム・コンテキスト・報酬にて設定することができる。
これにより、Bandit Storeに設定が格納され、学習の準備が整ったモデルが利用可能となる。
利用者は、ユーザーコンテキスト、表示されるアーム、クリックなどの報酬イベントなど、関連するイベントのタグ付けを設定するだけで良い。
Reward Collectorがこの設定通りに動き、クリックストリームからデータを収集し、バンディットのスコアを計算することができる。
このように、利用者は新しいモデルをデプロイする必要はなく、バンディットをオフ・ザ・シェルフの方法(棚から出して速攻で使える的な意味)で利用することができ、サイトの最適化と新しい機能の展開の実験を高速に進めることができる。
3. アルゴリズム
AdaptExは、古典的な方法や文脈的な方法など、様々なバンディットアルゴリズムを採用している。
古典的な手法としては、探索(Exploration)と活用(Exploitation)のための、Epsilon Greedy (EG)法、Thompson Sampling (TS)法、指数重みアルゴリズム(Exponential Weight Algorithm)を用いている。
EG法
1 パラメータε(0から1の間の値)を設定する。(εはランダムな行動を選択する確率を表す) 2 乱数を生成し、その値がε以下であれば、全ての可能な行動からランダムに一つを選択する(探索)。 3 乱数がεより大きい場合、これまでの経験から最も報酬が高かった行動を選択する(活用)。 4 選択した行動を実行し、報酬を観測する。 5 その報酬を使用して、行動の価値の推定を更新する。 2-5のステップを繰り返す。
TS法
1 各行動に対して、その報酬の確率分布(通常はベータ分布や正規分布など)の事前分布を設定する。 2 各行動の現在の確率分布からサンプルを一つ取得する。 3 サンプルの値が最も高い行動を選択して実行する。 4 選択した行動の結果として得られる報酬を観測する。 5 その報酬を使用して、選択した行動の報酬の確率分布を更新する。 2-5のステップを繰り返す。
Exponential-weight algorithm
1 各アクションに初期の重みを割り当てる。 2 あるタイムステップで、重みに基づいてアクションを選択する。 3 選択されたアクションの結果を観測する。 4 その結果に基づいて、全てのアクションの重みを更新する。 2-4のステップを繰り返す。
これらのアルゴリズムは、フィードバックが後から得られる場合に対して、効果的である。
本プラットフォームで最も一般的に使用するアルゴリズムはTS法で、各試行の報酬分布に対する事後分布を持っており、これを用いてどのアクションをするかを決める。
そして、各タイムステップで各アームの事後分布から値をサンプリングし、最も高いサンプリング値を持つアームを選択する。
アルゴリズムがより多くのデータを得ると、事後分布の正確性が上がり、最適なアームに収束する。
補足 TSの流れ 1 サンプリング TSは、各タイムステップで各アームの事後分布から1つの値(サンプル)を取り出す。 これは、各アームが次に与える報酬の予測値を取得するためにサンプルを取得する。 2 アームの選択 取り出したサンプルの中で最も大きい値を持つアームを選択する。 これは、そのタイムステップで最も高い報酬を期待できるアームを選択する行為。 3 事後分布の更新 アルゴリズムがより多くのデータ(報酬)を観測すると、事後分布は各アームの真の報酬分布についての知識を増やしていく。 具体的には、事後分布の分散が小さくなり、ピークが真の報酬の値に近づくことを意味する。 4 最適なアームへの収束 事後分布がより集中的になるにつれて、アルゴリズムは最も報酬が高いアーム、つまり最適なアームに収束する。 すなわち、アルゴリズムが繰り返しの試行を重ねることで、最も良いアームを確実に選択する能力が向上することを意味する。
AdaptExは、contextual variableに基づいて期待報酬を推定するため、linear contextual bandit algorithmも使用している。
モデルの更新では、Bayesian Logistic Regression (BLR)とRecursive Least Squares (RLS)を利用する。
BLR
1 事前分布の設定: ロジスティック回帰のパラメータに対して事前分布(通常は正規分布など)を設定する。 2 尤度の計算: 与えられたデータと現在のパラメータの値に基づいて尤度を計算する。 3 事後分布の更新: 事前分布と尤度を組み合わせて、パラメータの事後分布を計算する。 4 サンプリング: 事後分布からパラメータのサンプルを取得する。サンプリングには、MCMCなどが使われる。 5 予測: サンプリングされたパラメータを使用して、新しいデータを予測する。
RLS
1 初期化: パラメータの初期値と共分散行列の初期値を設定する。 2 データの更新: 新しいデータポイントが得られるたびに、モデルのパラメータを更新する。 3 パラメータの更新: 最小二乗法で、現在のパラメータと新しいデータを基に次のパラメータを計算する。
BLRは、バイナリ報酬(クリック or notなどの2値)の場合によく使用され、文脈と選択されたアームを考慮して正の報酬を受け取る確率を推定するため、ベイジアン推論を使用してロジスティック回帰モデルを更新する。
RLSは、連続的な報酬(100点満点で何点をつけるか?など)の場合に、文脈と選択されたアクションを考慮して期待報酬を推定するためのオンライン線形回帰モデルを使用する。
TSとEGに加えて、Inverse Gap Weighting (IGW)も用いている。
これは、期待報酬の間のギャップに比例してアームを選択する。
Inverse Gap Weighting
1 ギャップの特定: 欠損値やギャップが存在する位置を特定する。 2 重みの計算: ギャップの前後のデータポイントまでの距離に基づいて、それぞれのデータポイントに重みを計算する。 ギャップが大きい場合、近くのデータポイントには大きな重みが、遠くのデータポイントには小さな重みをつけるようにする。 3 補間: 計算された重みを使用して、欠損値やギャップを埋めるための値を推定する。 重み付きの平均などを用いる。
ランク付け(ratingや比較して順位をつけるようなタスク)には、Cascading Banditsを使用する。
これは、ユーザーに表示するアイテムのシーケンスを選択するためにTSを使用し、各アイテムは、表示された前のアイテムを考慮してクリックされる確率に基づいて選択する方法である。
Cascading Bandits
1 表示順序: システムは複数のアイテムを順序付けてユーザーに表示する。 2 ユーザーのインタラクション: ユーザーは上から順にアイテムを評価し、興味を持った最初のアイテムに反応(クリックなど)する。それ以降のアイテムは無視されると仮定する。 3 報酬: クリックまたは選択されたアイテムのみが報酬を得る。それ以前のアイテムは報酬がなく、それ以降のアイテムは評価されないため報酬の情報がないとして扱う。
TSとCascading Bandits
1 アイテムの選択: TSを使用して、最初のアイテムを選択する。これは、そのアイテムがクリックされる確率が最も高いと予測されるものを選択することになる。 2 続くアイテムの選択: 一度アイテムが選択されると、次に表示するアイテムは、前に表示されたアイテムを考慮して選択する。 具体的には、前のアイテムが表示された後に次のアイテムがクリックされる確率に基づいて選択されることになる。 3 シーケンスの形成: ユーザーに表示するアイテム数分、これを繰り返す。 ユーザーが上から順にアイテムを評価し、興味を持った最初のアイテムをクリックするという仮定に基づき、 各アイテムは、前に表示されたアイテムに基づいて選択され、そのアイテムがクリックされる確率を最大化するように順序付けするようなイメージ。
複数の目的がある場合、その複数の目的を達成するための行動を選択する必要がある。
この場合は、Generalized Gini Index Aggrigation Functionを利用し、各目的の報酬を数値化する(スカラー化する)ことで、パレートフロント上の最適解を発見するようなアプローチをする。
パレートフロント
複数の目的関数がある場合に、その複数の目的関数の最大点を発見するアプローチ。
また、実運用時の低レイテンシ要件に対応するため、これらの実行を軽量化する必要がある。
これに対しAdaptExでは、レイテンシが発生しやすいアプリケーションのすべてのアームサンプリングリクエストの最良のアーム決定プロセスにGreedy Searchを組み込んでいる。
すべてのアームオプションを網羅的に反復する代わりに貪慾法を用いることで、リクエスト速度を短くし、良好な品質の近似ソリューションを発見する。
Greedy Searh
貪欲法。最適化問題や探索問題を解くための考え方。 「後先のことを考えず、その場その場での選択を繰り返していく」という考え方に基づき、次の行動を決める。
4. 利用例
AdaptExは、任意のプロダクトチームがMulti Arm Banditを簡単に設定できる。
チームは、仮説に最も適しているアームと文脈的特徴の設定を選択することができ、また、顧客のエンゲージメント、ロイヤルティ、予約(アクション)を含むさまざまなビジネス指標と整合するように報酬を設定することができる。
バンディットによって決定する学習とテストの流れは以下の通り。
まず、バンディットは学習フェーズとして、異なる経験を探索し、受け取ったユーザーフィードバックから学習する。
次に、学習フェーズは、バンディットによって決定された最良のバリアント(「アーム」)を固定することで停止する。
バンディットは探索を停止し、学習した結果の活用に移る。
この固定されたバンディットは、選択されたビジネス指標に対して変更が統計的に有意であることを確認するため、A/Bテストで比較していく。
この柔軟性と既存の実験方法との互換性は、Expedia Groupの複数のブランドやビジネス機能における様々な事例を生んでいる。
非文脈的テストの一例として、ウェブサイトモジュールの最適化がある。
例えば、10個以下の候補のコンテンツがある場合における、最適な選択などである。
このような場合、通常は複数のA/Bテストを実施して10個の中から最適なものを発見することになるが、本プラットフォームを使うと、1週間程度で最も良いコンテンツを見つけることができ通常の1/10くらいの期間でこれを実現する。
また、ページ上に表示するための複数のモジュールコンポーネントがあり、その組み合わせの最適化をしたい場合にも利用でき、コンテンツ・デザイン・配置をユーザーに合わせて〜100の異なる組み合わせを設定することもできる。
バンディットは、旅行のタイプや販売地点などの特徴で分類される1000以上の顧客セグメントに対して、パーソナライズされた選択も可能である。
このようなテストと最適化をしたければ、利用量(取得できるデータの数)で上下はあるが、大体2〜4週間で実現できる。
伝統的なA/Bテストでは、4週間でこれを実現することは不可能である。
さらに、AdaptExはもっと複雑なテストも実現して、最適解を発見することができた。
例えば、Hotels.comの各宿泊ページのサムネイル画像の最適化や、ページ上の数十のアイテムやモジュールのランク付けを100万を超える組み合わせの最適化の例がある。
Hotels.comの記事
最後に、AdaptExはコールドスタートの問題を克服することにも使える。
例えば、履歴データが利用できないような新しい顧客に対する最適なレコメンド戦略を決定することや、顧客の行動に関するデータがない新しいアイテムの最適な配置を見つけることができる。
文脈固有のレコメンドと、新しいアイテムの最適なプロダクト配置にAdaptExを活用することで、リアルタイムで学習するを支援することができる。
AdaptExはリリースしてから、非常に良い結果を残し続けている。
プラットフォームの成功は、MABアルゴリズムが明らかに劣っているオプションを迅速に破棄することで、大量のアームの選択を迅速にテストする能力が鍵である。
プラットフォームの高度にカスタマイズ可能なセルフサービス形式は、さまざまなビジネスニーズを持つ幅広いチームが、より迅速なパーソナライズされた機能のテストと開発を利用することを可能にした。
5. 今後の取り組み
以下の観点でAdaptEXを改良する予定である。
非線形アプローチ
時間的な制約から、線形モデルを用いたアプローチでこれまで成功を収めているが、線形モデルでは表現力が限定的であり、より複雑な報酬に対応するには不十分な可能性がある。
さらなるパーソナライゼーションを実現するため、ニューラルネットワークのような非線形アルゴリズムを採用することを検討している。
強化学習
すべてのユーザーのインタラクションが単一のステップに限定されるわけではない。
「ホームページにアクセスしてから予約するまで」は、複数のステップから為るのが一般的である。
しかし、Multi Arm Banditはデフォルトでは、この複数ステップの関連性を考慮したモデル化するようにはまだ設計されていない。
よって、連続的な意思決定支援の方法として、強化学習を活用することを検討している。
以上!
なんか分かったようなわからんような。
スモールに試してみたいんだけど、できるかな・・・???